序
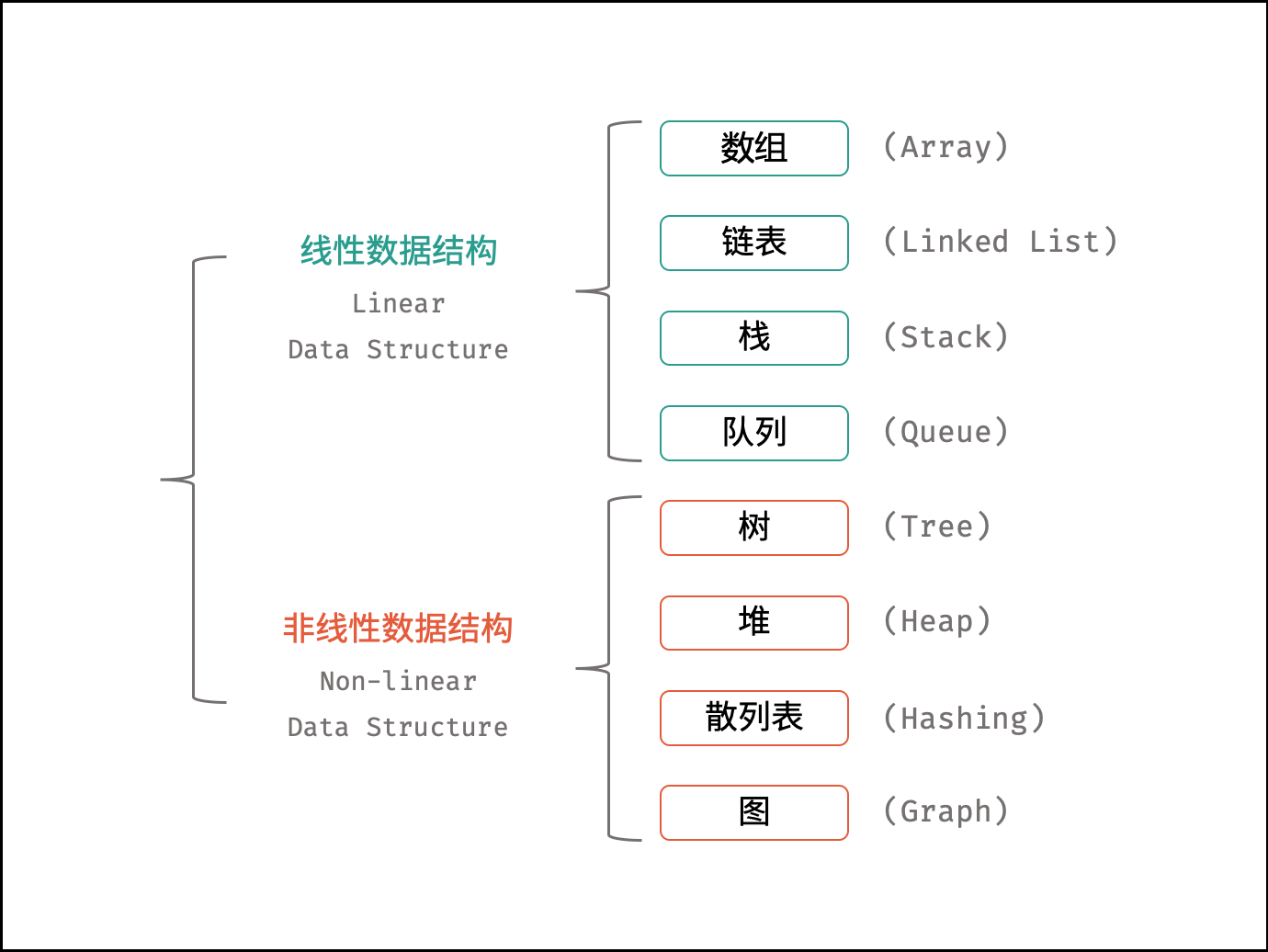
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
常见的数据结构有如下:
数组
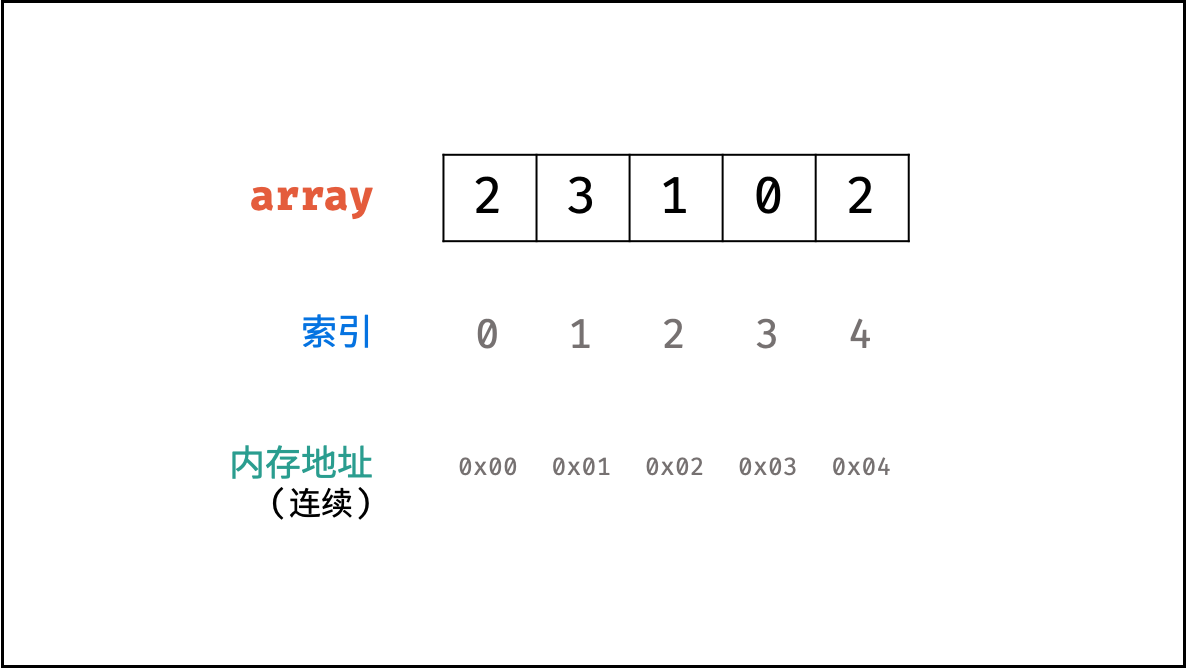
数组是讲相同类型的元素存储于连续内存空间的数据结构,长度不可变。
初始化时需要给定长度并对每个索引元素赋值:
1 | // 初始化一个长度为 5 的数组 array |
或者可以使用直接复制的初始化方式:
1 | int[] array = {2,3,1,0,2} |
“可变数组”是经常使用的数据结构,其基于数组和扩容机制实现,相比普通数组更加灵活.常用的操作有:访问元素、添加元素、删除元素:
1 | //初始化可变数组 |
LC485.最大连续1的个数
给定一个二进制数组 nums , 计算其中最大连续 1 的个数。
示例 1:
输入:nums = [1,1,0,1,1,1]
输出:3
解释:开头的两位和最后的三位都是连续 1 ,所以最大连续 1 的个数是 3.
示例 2:
输入:nums = [1,0,1,1,0,1]
输出:2
提示:
1 <= nums.length <= 105
nums[i] 不是 0 就是 1.
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/max-consecutive-ones
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

count记录当前连续1个数,遇到0时在当前count与result中取最大值赋给result,并重置当前count重新计数。
Java
1 | class Solution { |
Python3
1 | class Solution: |
LC283.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
输入: nums = [0,1,0,3,12]
输出: [1,3,12,0,0]
示例 2:
输入: nums = [0]
输出: [0]
提示:
1 <= nums.length <= 104
-231 <= nums[i] <= 231 - 1
进阶:你能尽量减少完成的操作次数吗?
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/move-zeroes
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

遍历数组,当前不为0则赋给索引为0的位置并index+1,
非0元素都移动到前面去后,
从i=index出发,对剩下的都赋0
Java
1 | class Solution { |
Python3
1 | class Solution: |
LC27.移动元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
说明:
为什么返回数值是整数,但输出的答案是数组呢?
请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
你可以想象内部操作如下:
// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
int len = removeElement(nums, val);
// 在函数里修改输入数组对于调用者是可见的。
// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
for (int i = 0; i < len; i++) {
print(nums[i]);
}
示例 1:
输入:nums = [3,2,2,3], val = 3
输出:2, nums = [2,2]
解释:函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。你不需要考虑数组中超出新长度后面的元素。例如,函数返回的新长度为 2 ,而 nums = [2,2,3,3] 或 nums = [2,2,0,0],也会被视作正确答案。
示例 2:
输入:nums = [0,1,2,2,3,0,4,2], val = 2
输出:5, nums = [0,1,4,0,3]
解释:函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。注意这五个元素可为任意顺序。你不需要考虑数组中超出新长度后面的元素。
提示:
0 <= nums.length <= 100
0 <= nums[i] <= 50
0 <= val <= 100
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-element
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

双指针,i找到val时停下,j找不到val时停下
i,j值交换
i >= j时,循环停止。前半部分是有效部分,存储不等于val的元素,后半部分是无效部分,存储等于val的元素,需要返回前半部分
判断如果nums[l] == val,代表l的值等于当前数组的长度,直接返回
否则返回l + 1
Java
1 | class Solution { |
Python3
1 | class Solution: |
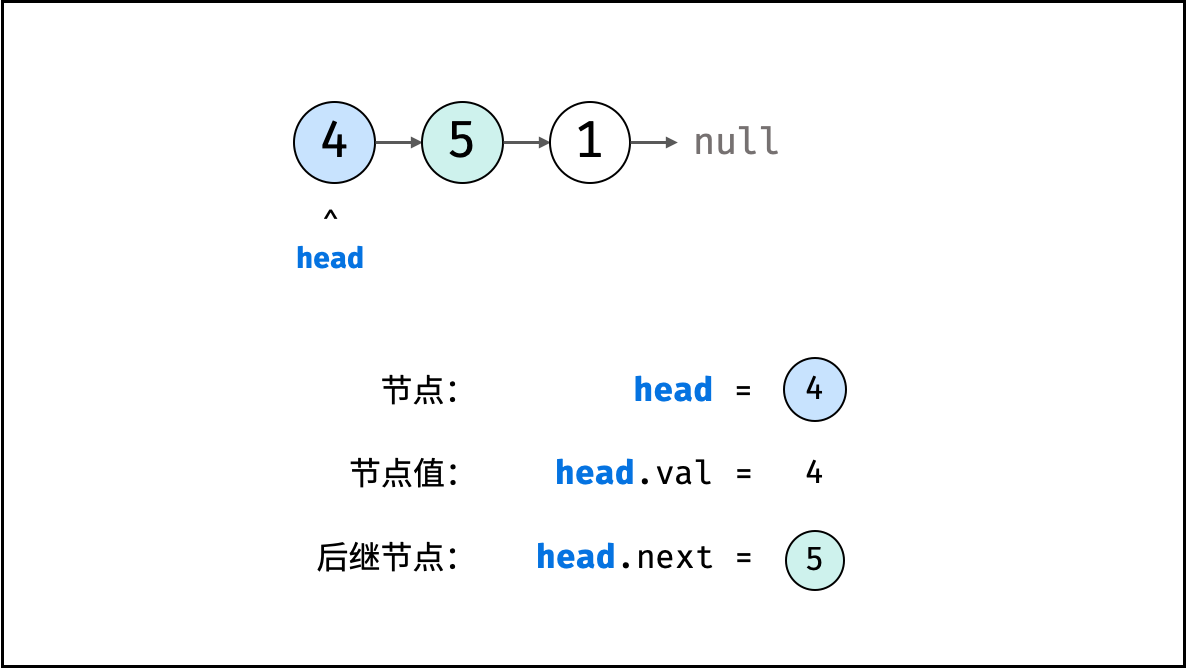
链表
链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的。链表的节点对象具有两个成员变量:「值 val」,「后继节点引用 next」 。
1 | class ListNode { |
建立链表需要实例化每个节点,并构建各节点的引用指向。
1 | //实例化节点 |

LC203.移除链表元素
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例 1:
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
示例 2:
输入:head = [], val = 1
输出:[]
示例 3:
输入:head = [7,7,7,7], val = 7
输出:[]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/remove-linked-list-elements
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | class Solution { |
Python3
1 | class Solution: |
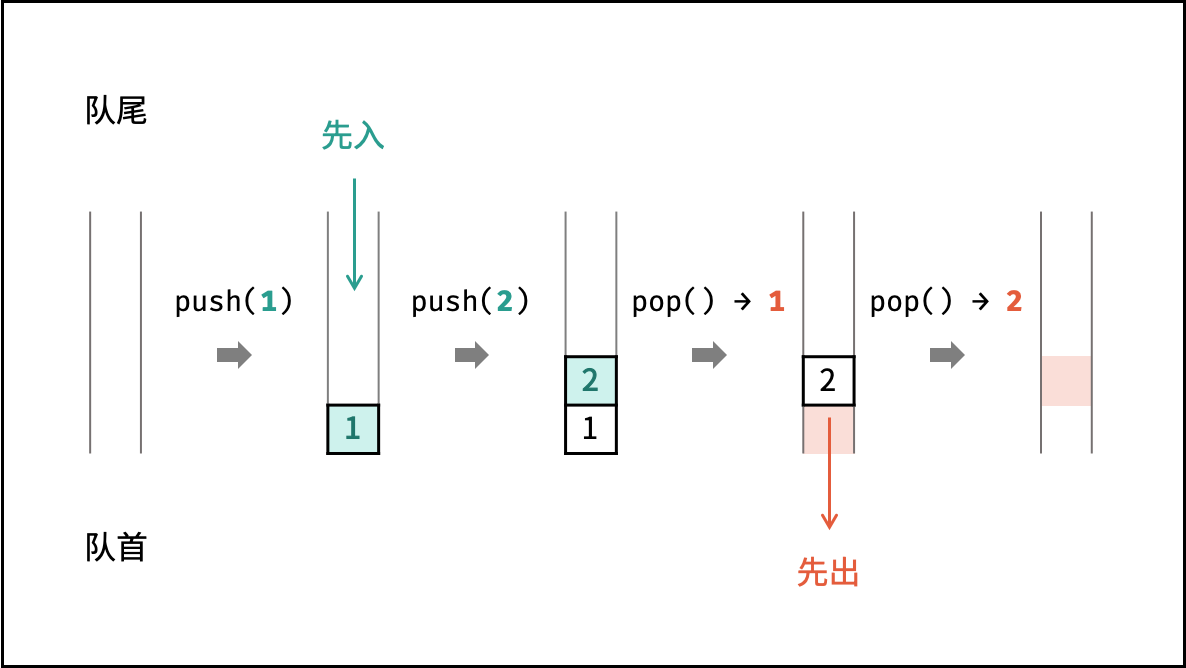
队列
队列是一种具有 「先入先出」 特点的抽象数据结构,可使用链表实现。
1 | Queue<Integer> queue = new LinkedList<>(); |
如下图所示,通过常用操作「入队 push()」,「出队 pop()」,展示了队列的先入先出特性。
1 | queue.offer(1); //元素1入队 |

LC933.最近的请求次数
写一个 RecentCounter 类来计算特定时间范围内最近的请求。
请你实现 RecentCounter 类:
RecentCounter() 初始化计数器,请求数为 0 。
int ping(int t) 在时间 t 添加一个新请求,其中 t 表示以毫秒为单位的某个时间,并返回过去 3000 毫秒内发生的所有请求数(包括新请求)。确切地说,返回在 [t-3000, t] 内发生的请求数。
保证 每次对 ping 的调用都使用比之前更大的 t 值。
示例 1:
输入:
[“RecentCounter”, “ping”, “ping”, “ping”, “ping”]
[[], [1], [100], [3001], [3002]]
输出:
[null, 1, 2, 3, 3]
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/number-of-recent-calls
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | import java.util.LinkedList; |
Python3
1 | class RecentCounter: |
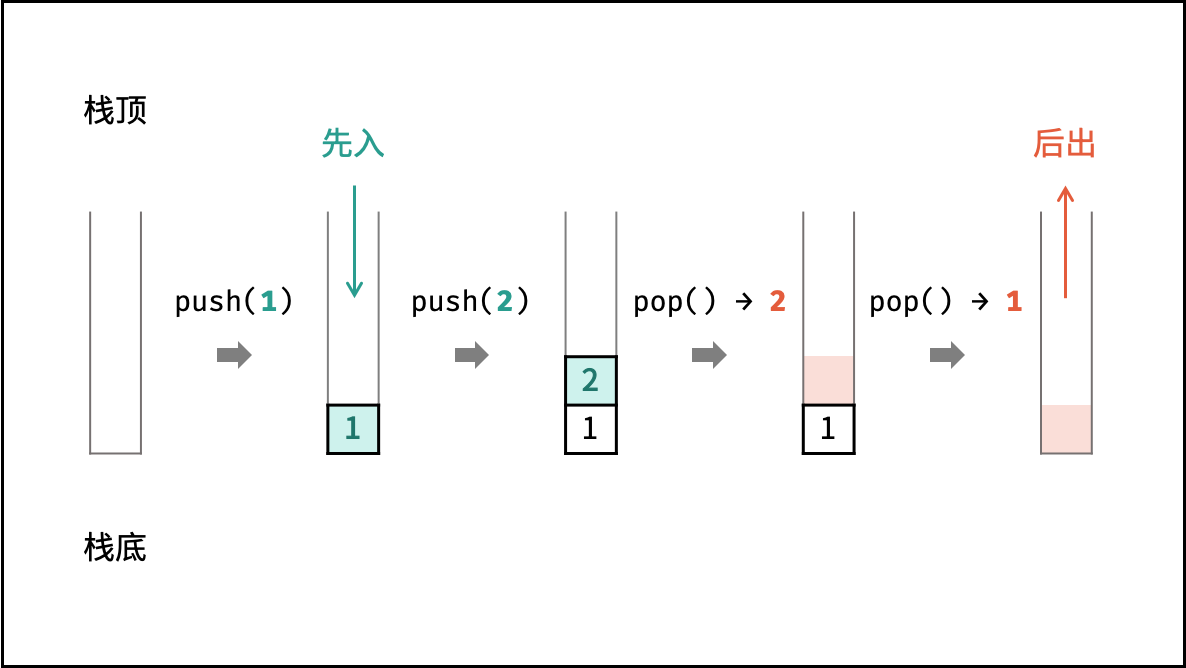
栈
栈是一种具有 「先入后出」 特点的抽象数据结构,可使用数组或链表实现。
1 | Stack<Integer> stack = new Stack<>(); |
如下图所示,通过常用操作「入栈 push()」,「出栈 pop()」,展示了栈的先入后出特性。
1 | stack.push(1); //元素1入栈 |
注意:通常情况下,不推荐使用 Java 的
Vector以及其子类Stack,而一般将LinkedList作为栈来使用。
1 | LinkedList<Integer>stack = new LinkedList<>() |

LC20.有效的括号
给定一个只包括 ‘(‘,’)’,’{‘,’}’,’[‘,’]’ 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
左括号必须用相同类型的右括号闭合。
左括号必须以正确的顺序闭合。
示例 1:
输入:s = “()”
输出:true
示例 2:
输入:s = “()[]{}”
输出:true
示例 3:
输入:s = “(]”
输出:false
示例 4:
输入:s = “([)]”
输出:false
示例 5:
输入:s = “{[]}”
输出:true
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/valid-parentheses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | class Solution { |
Python3
1 | class Solution: |
LC496.下一个更大元素
nums1 中数字 x 的 下一个更大元素 是指 x 在 nums2 中对应位置 右侧 的 第一个 比 x 大的元素。
给你两个 没有重复元素 的数组 nums1 和 nums2 ,下标从 0 开始计数,其中nums1 是 nums2 的子集。
对于每个 0 <= i < nums1.length ,找出满足 nums1[i] == nums2[j] 的下标 j ,并且在 nums2 确定 nums2[j] 的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是 -1 。
返回一个长度为 nums1.length 的数组 ans 作为答案,满足 ans[i] 是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2].
输出:[-1,3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
- 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。
- 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
示例 2:
输入:nums1 = [2,4], nums2 = [1,2,3,4].
输出:[3,-1]
解释:nums1 中每个值的下一个更大元素如下所述:
- 2 ,用加粗斜体标识,nums2 = [1,2,3,4]。下一个更大元素是 3 。
- 4 ,用加粗斜体标识,nums2 = [1,2,3,4]。不存在下一个更大元素,所以答案是 -1 。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/next-greater-element-i
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | import java.util.Stack; |
Python3
1 | class Solution: |
散列表
散列表是一种非线性数据结构,通过利用 Hash 函数将指定的「键 key」映射至对应的「值 value」,以实现高效的元素查找。
设想一个简单场景:小力、小特、小扣的学号分别为 10001, 10002, 10003 。
现需求从「姓名」查找「学号」。
则可通过建立姓名为 key ,学号为 value 的散列表实现此需求,代码如下:
1 | // 初始化散列表 |
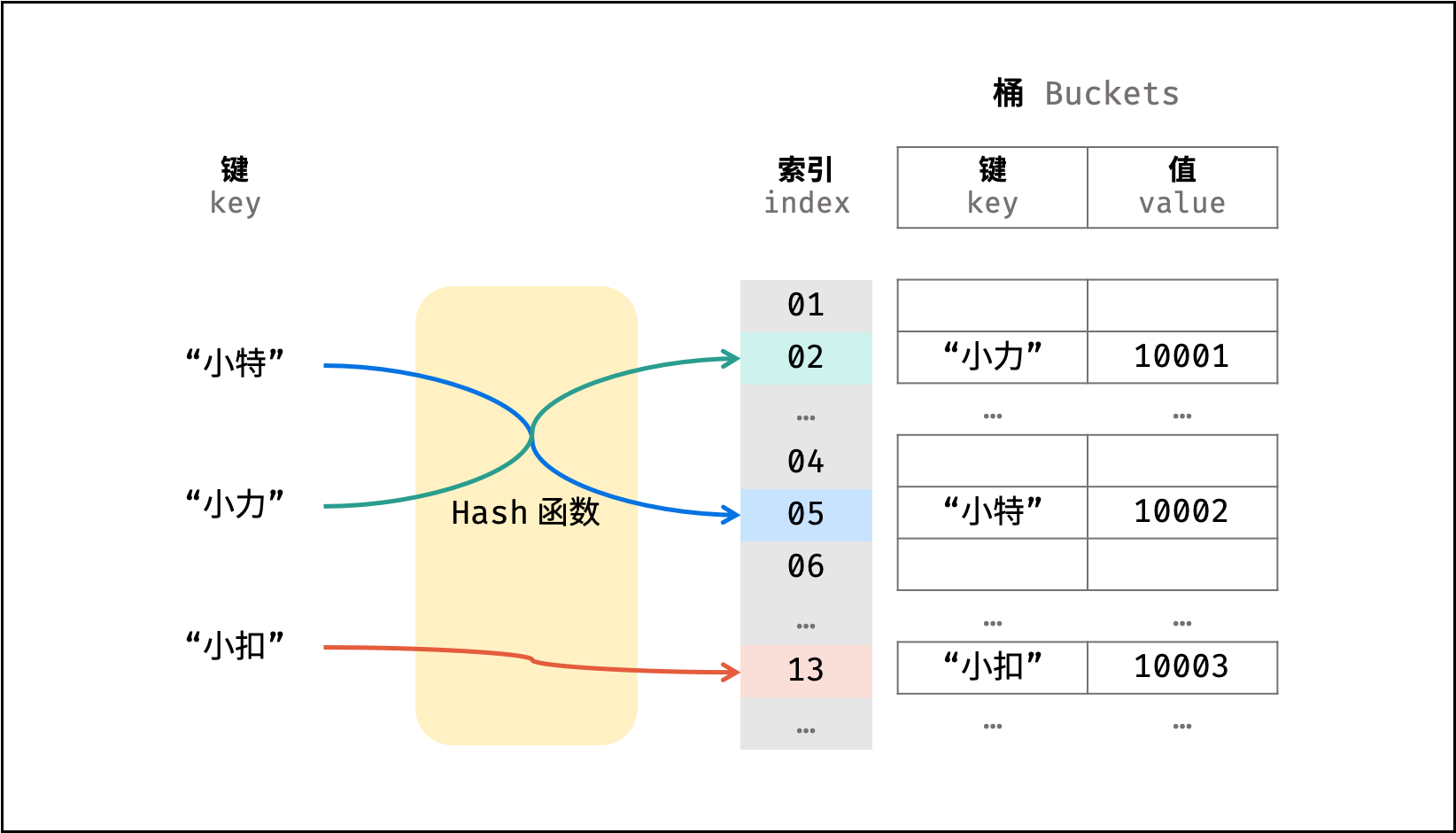
Hash函数设计Demo
假设需求:从「学号」查找「姓名」。
将三人的姓名存储至以下数组中,则各姓名在数组中的索引分别为 0, 1, 2 。
1 | String[] names = {"小力","小特","小扣"}: |
此时,我们构造一个简单的 Hash 函数( %% 为取余符号 ),公式和封装函数如下所示:
hash(key) = (key - 1) % 10000
1 | int hash(int id) { |
则我们构建了以学号为 key 、姓名对应的数组索引为 value 的散列表。利用此 Hash 函数,则可在 O(1)O(1) 时间复杂度下通过学号查找到对应姓名,即:
1 | names[hash(10001)] // 小力 |
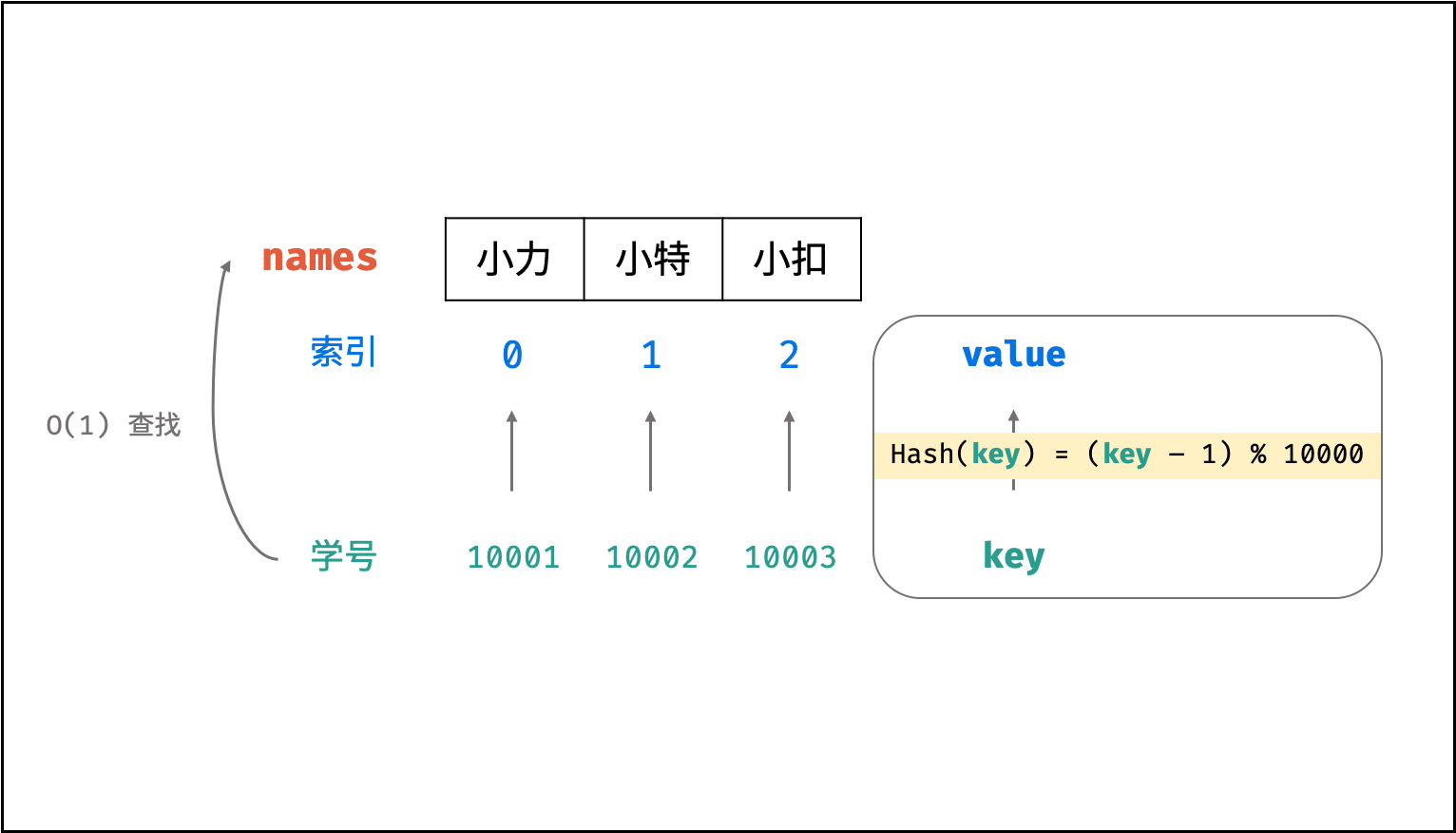
以上设计只适用于此示例,实际的 Hash 函数需保证低碰撞率、 健壮性等,以适用于各类数据和场景。

LC217.存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1]
输出:true
示例 2:
输入:nums = [1,2,3,4]
输出:false
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/contains-duplicate
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 |
|
Python3
1 | class Solution: |
LC389.找不同
给定两个字符串 s 和 t ,它们只包含小写字母。
字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
请找出在 t 中被添加的字母。
示例 1:
输入:s = “abcd”, t = “abcde”
输出:”e”
解释:’e’ 是那个被添加的字母。
示例 2:
输入:s = “”, t = “y”
输出:”y”
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/find-the-difference
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

S里就+1,T里就-1,+1-1抵消
Java
1 | class Solution { |
Python3
1 | class Solution: |
集合
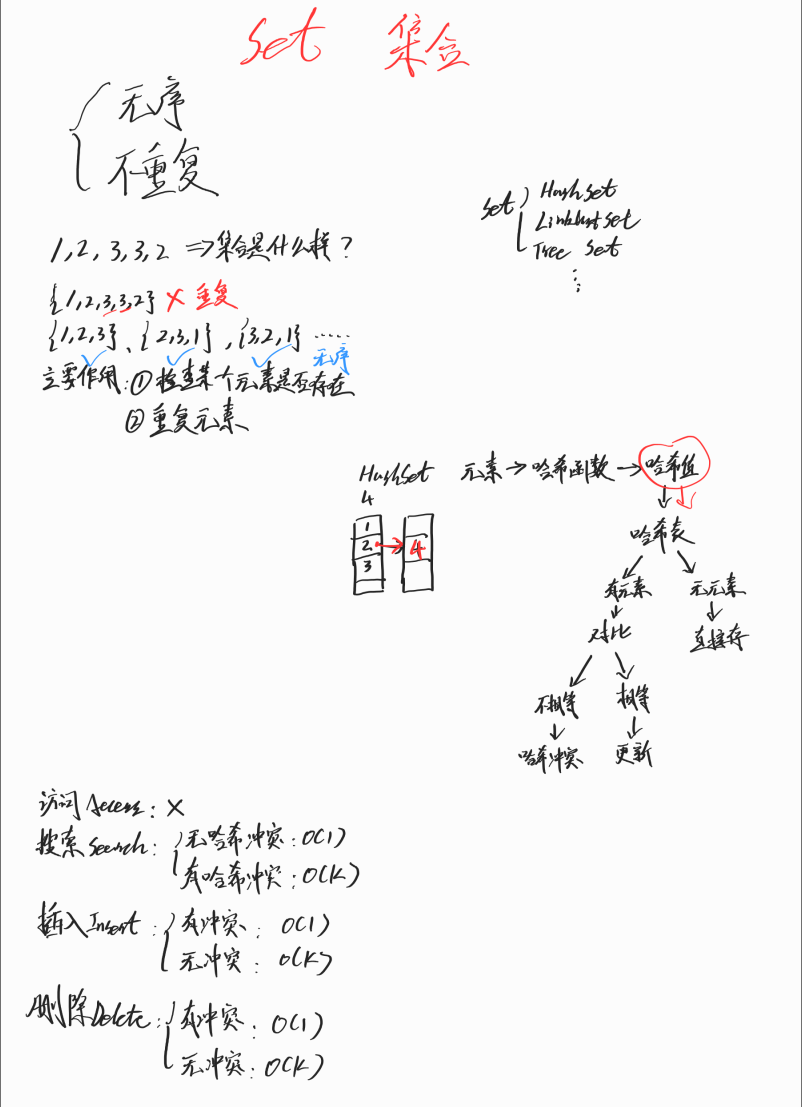
LC217.存在重复元素
给你一个整数数组 nums 。如果任一值在数组中出现 至少两次 ,返回 true ;如果数组中每个元素互不相同,返回 false 。
示例 1:
输入:nums = [1,2,3,1]
输出:true
示例 2:
输入:nums = [1,2,3,4]
输出:false
示例 3:
输入:nums = [1,1,1,3,3,4,3,2,4,2]
输出:true
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/contains-duplicate
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | import java.util.Arrays; |
Python3
1 | class Solution: |
LC705.设计哈希集合
不使用任何内建的哈希表库设计一个哈希集合(HashSet)。
实现 MyHashSet 类:
void add(key) 向哈希集合中插入值 key 。
bool contains(key) 返回哈希集合中是否存在这个值 key 。
void remove(key) 将给定值 key 从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
示例:
输入:
[“MyHashSet”, “add”, “add”, “contains”, “contains”, “add”, “contains”, “remove”, “contains”]
[[], [1], [2], [1], [3], [2], [2], [2], [2]]
输出:
[null, null, null, true, false, null, true, null, false]
解释:
MyHashSet myHashSet = new MyHashSet();
myHashSet.add(1); // set = [1]
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(1); // 返回 True
myHashSet.contains(3); // 返回 False ,(未找到)
myHashSet.add(2); // set = [1, 2]
myHashSet.contains(2); // 返回 True
myHashSet.remove(2); // set = [1]
myHashSet.contains(2); // 返回 False ,(已移除)
提示:
0 <= key <= 106- 最多调用
104次add、remove和contains
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/design-hashset
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

Java
1 | class MyHashSet { |
Python3
1 | class MyHashSet: |
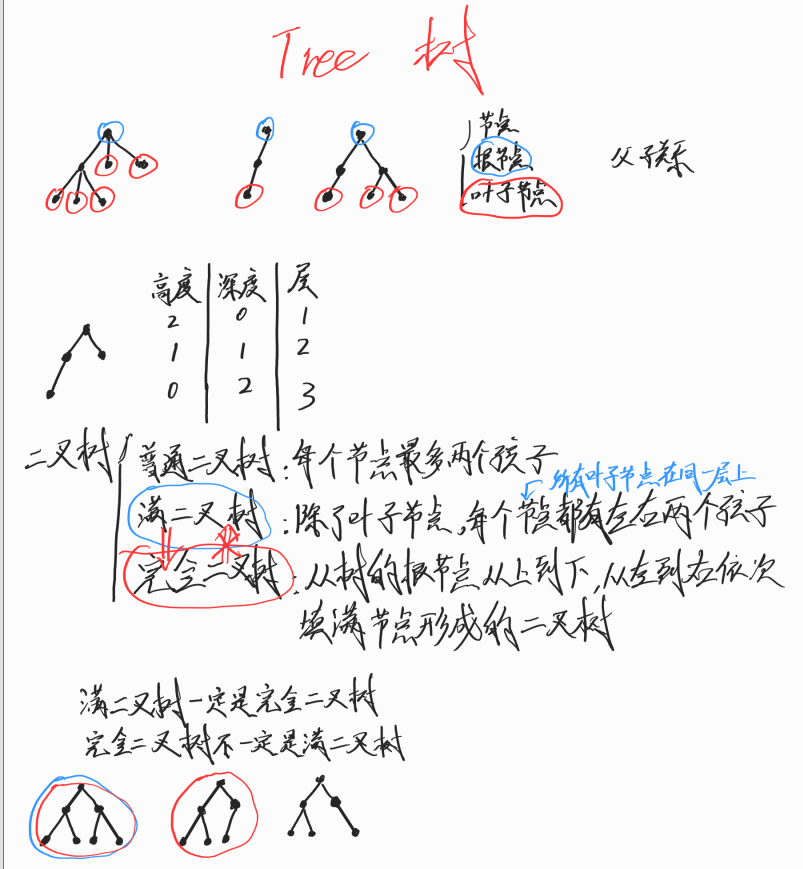
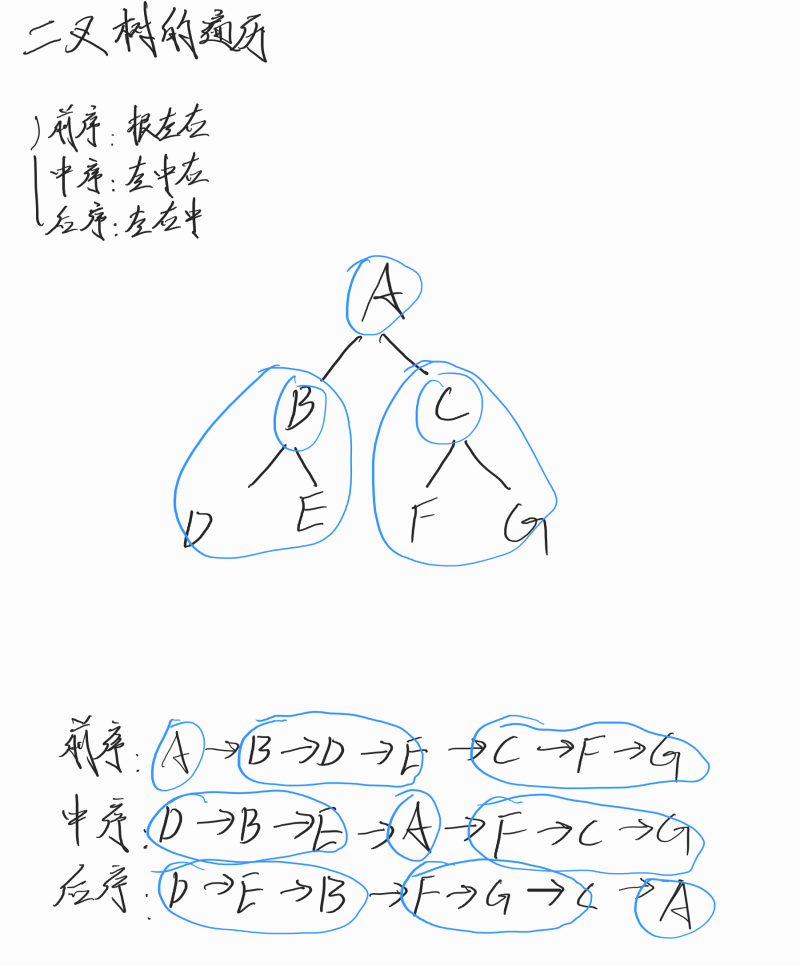
树
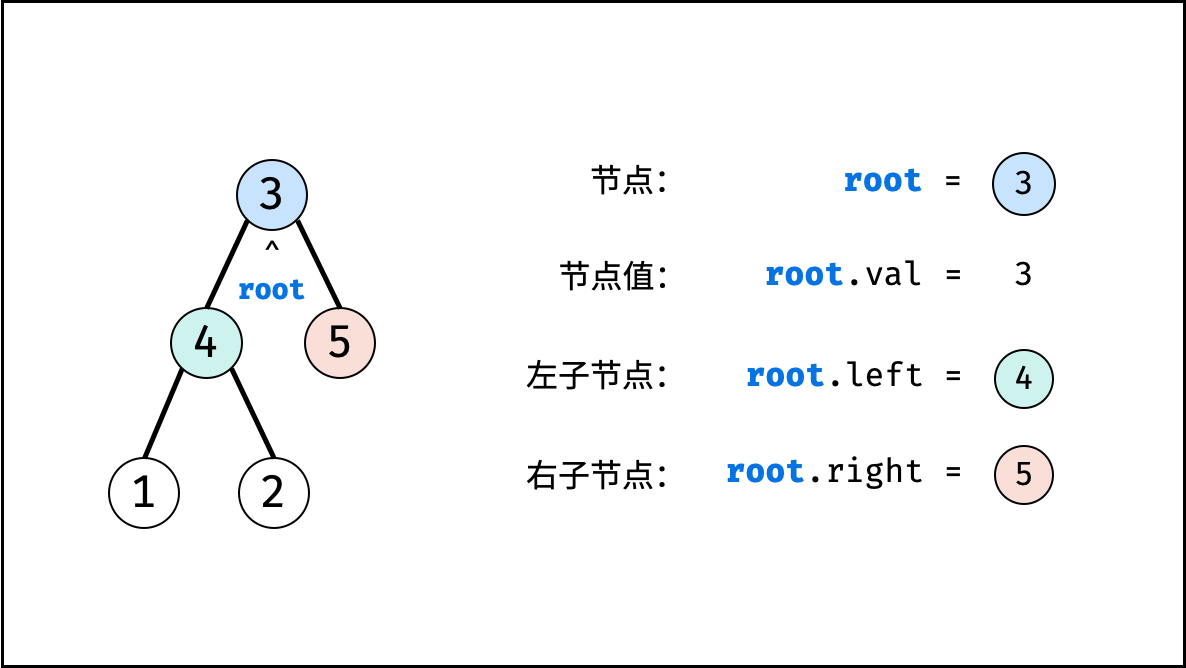
树是一种非线性数据结构,根据子节点数量可分为 「二叉树」 和 「多叉树」,最顶层的节点称为「根节点 root」。以二叉树为例,每个节点包含三个成员变量:「值 val」、「左子节点 left」、「右子节点 right」
1 | class TreeNode { |
如下图所示,建立此二叉树需要实例化每个节点,并构建各节点的引用指向。
1 | // 初始化节点 |
堆
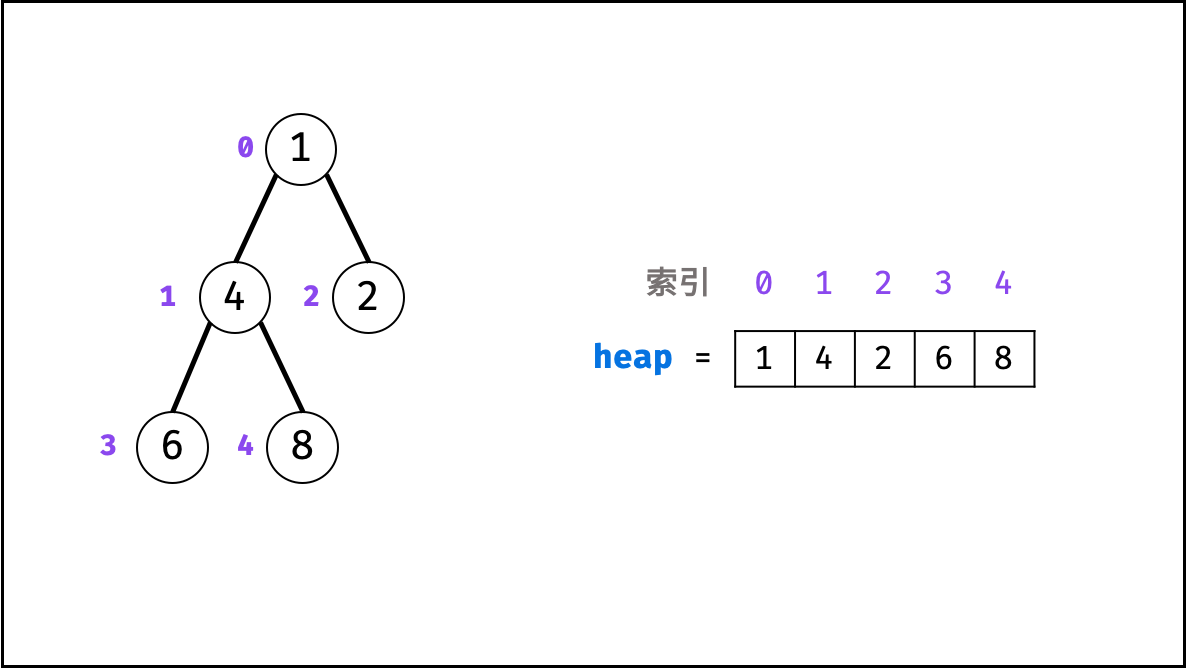
堆是一种基于「完全二叉树」的数据结构,可使用数组实现。以堆为原理的排序算法称为「堆排序」,基于堆实现的数据结构为「优先队列」。堆分为「大顶堆」和「小顶堆」,大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
完全二叉树定义: 设二叉树深度为 k ,若二叉树除第 k 层外的其它各层(第 11 至 k-1 层)的节点达到最大个数,且处于第 k 层的节点都连续集中在最左边,则称此二叉树为完全二叉树。
如下图所示,为包含 1, 4, 2, 6, 8 元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。
通过使用「优先队列」的「压入 push()」和「弹出 pop()」操作,即可完成堆排序,实现代码如下:
1 | // 初始化小顶堆 |

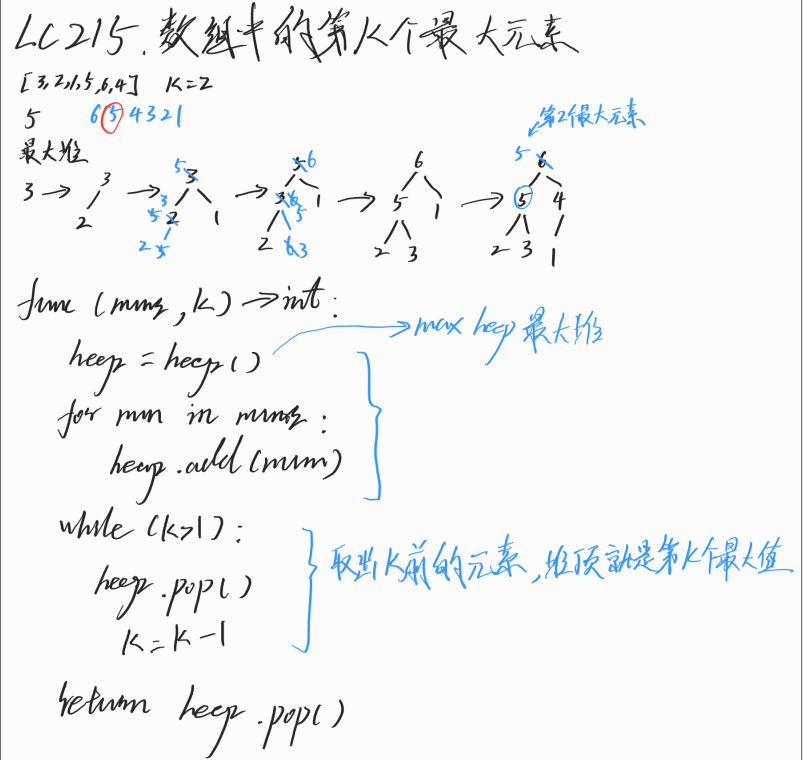
LC215.数组中的第k个最大元素
给定整数数组 nums 和整数 k,请返回数组中第 k 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
示例 1:
输入: [3,2,1,5,6,4], k = 2
输出: 5
示例 2:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/kth-largest-element-in-an-array
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
Java
1 | import java.util.Collections; |
Python3
1 | import heapq |
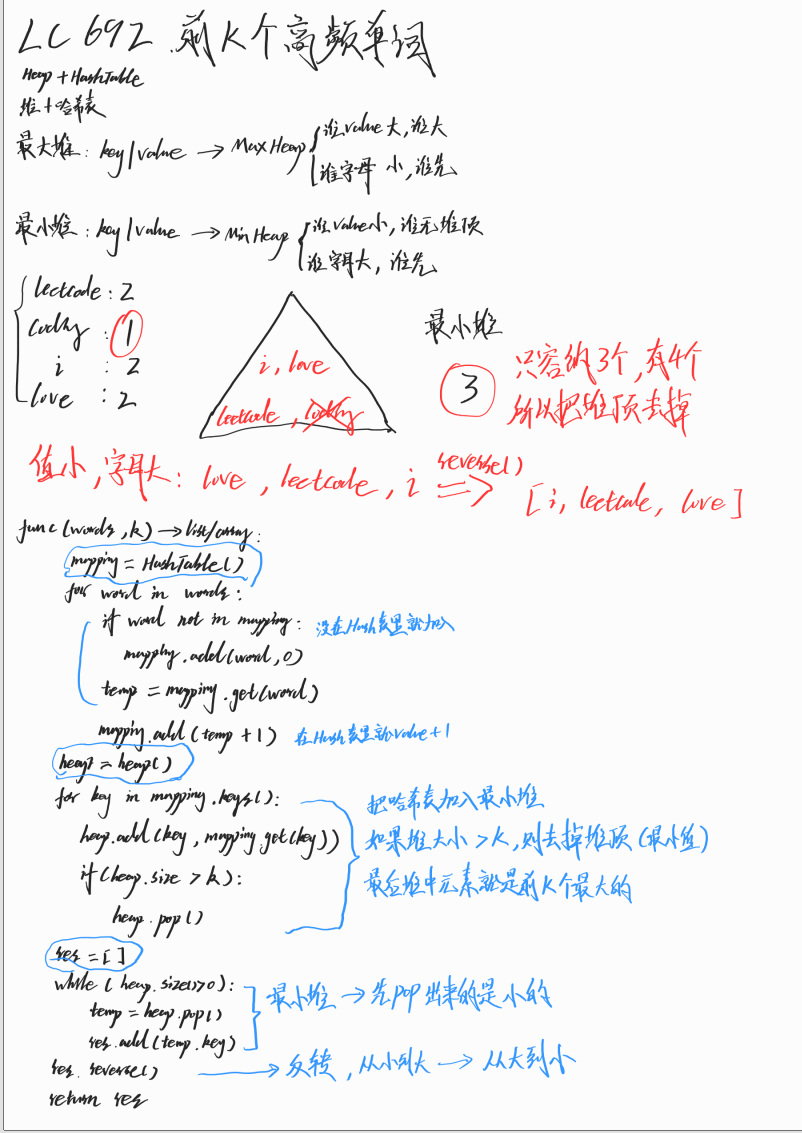
*LC.692.前K个高频单词
给定一个单词列表 words 和一个整数 k ,返回前 k 个出现次数最多的单词。
返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率, 按字典顺序 排序。
示例 1:
输入: words = [“i”, “love”, “leetcode”, “i”, “love”, “coding”], k = 2
输出: [“i”, “love”]
解析: “i” 和 “love” 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 “i” 在 “love” 之前。
示例 2:
输入: [“the”, “day”, “is”, “sunny”, “the”, “the”, “the”, “sunny”, “is”, “is”], k = 4
输出: [“the”, “is”, “sunny”, “day”]
解析: “the”, “is”, “sunny” 和 “day” 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/top-k-frequent-words
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
Java
1 | import java.util.Collections; |
Python3
1 | import heapq |
图
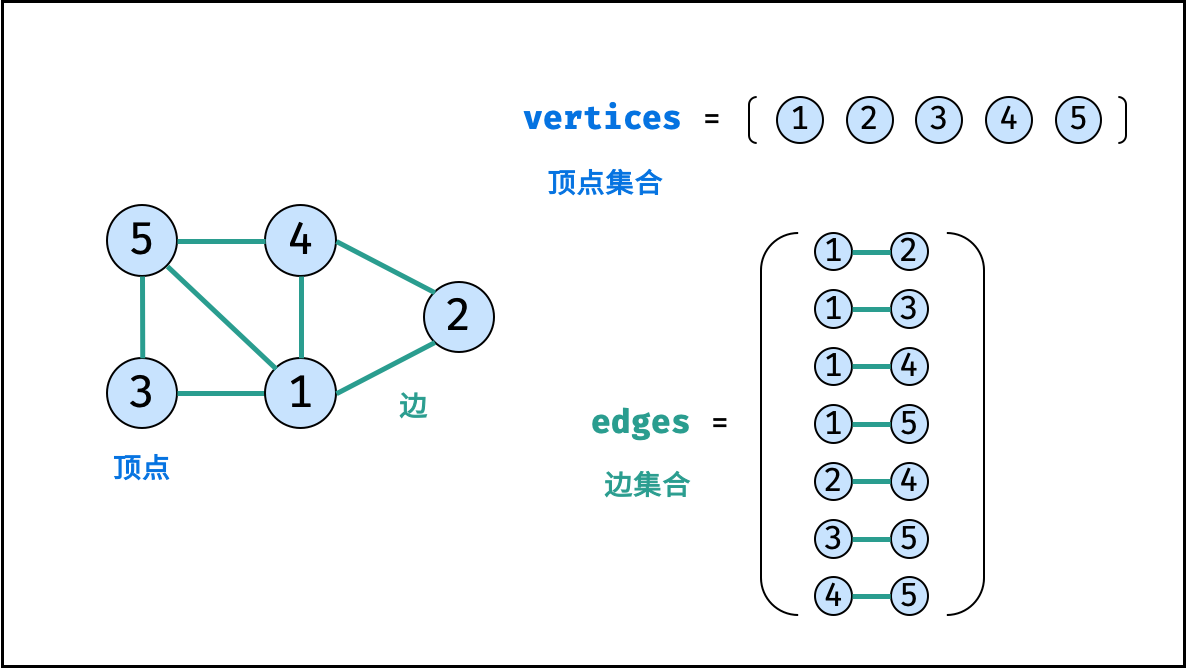
图是一种非线性数据结构,由「节点(顶点)vertex」和「边 edge」组成,每条边连接一对顶点。根据边的方向有无,图可分为「有向图」和「无向图」。本文 以无向图为例 开展介绍。
如下图所示,此无向图的 顶点 和 边 集合分别为:
顶点集合: vertices = {1, 2, 3, 4, 5}
边集合: edges = {(1, 2), (1, 3), (1, 4), (1, 5), (2, 4), (3, 5), (4, 5)}
邻接矩阵: 使用数组 verticesvertices 存储顶点,邻接矩阵 edgesedges 存储边; edges[i][j]edges[i][j] 代表节点 i + 1i+1 和 节点 j + 1j+1 之间是否有边。
1
2
3
4
5
6
7vertices = [1, 2, 3, 4, 5]
edges = [[0, 1, 1, 1, 1],
[1, 0, 0, 1, 0],
[1, 0, 0, 0, 1],
[1, 1, 0, 0, 1],
[1, 0, 1, 1, 0]]邻接表: 使用数组 verticesvertices 存储顶点,邻接表 edgesedges 存储边。 edgesedges 为一个二维容器,第一维 ii 代表顶点索引,第二维 edges[i]edges[i] 存储此顶点对应的边集和;例如 edges[0] = [1, 2, 3, 4]edges[0]=[1,2,3,4] 代表 vertices[0]vertices[0] 的边集合为 [1, 2, 3, 4][1,2,3,4] 。
1
2
3
4
5
6vertices = [1, 2, 3, 4, 5]
edges = [[1, 2, 3, 4],
[0, 3],
[0, 4],
[0, 1, 4],
[0, 2, 3]]邻接矩阵 VS 邻接表 :
邻接矩阵的大小只与节点数量有关,即 N^2,其中 N 为节点数量。因此,当边数量明显少于节点数量时,使用邻接矩阵存储图会造成较大的内存浪费。
因此,邻接表 适合存储稀疏图(顶点较多、边较少); 邻接矩阵 适合存储稠密图(顶点较少、边较多)。
1 | 作者:Krahets |
