一、项目开发目的
随着科技的高速发展,人们的生活节奏也越来越快。忙碌的都市生活让许多年轻一族习惯于在餐饮外卖平台上进行订餐。“今天吃是什么”这个问题在生活中也越来越普遍。为了解决人们对于外卖餐饮的选择问题,本项目随之诞生。本项目的开发目的就在于为人们提供个性化的菜品推荐系统,解决人们选择困难的问题。
二、项目开发环境
1.项目设计组件及语言
1.hadoop
2.spark
3.Hive
4.spark
5.mysql
6.java
2.环境搭建流程
1.搭建Hadoop分布式集群
2.spark安装配置
3.mysql安装配置
4.hive安装配置
5.scala安装配置
6.idea配置maven仓库、scalasdk
3.数据来源及构成
数据来源是网站的数据库(MySQL)中保存着的菜品数据集

数据集用JSON格式存储,数据结构固定。每条记录由如下属性组成:UserID、Rating、ReviewTime、Review、MealID。其中,UserID为用户ID、Rating为用户评分、ReviewTime为评论时间戳、Review为用户评论、MealID为菜品ID。
本数据源包含38384条总记录数、总用户数为5130、总菜品数为1685,最高评分为5.0,最低评分为1.0。
工程文件:https://github.com/zhuozhuo233/Catering-recommendation
三、项目功能实现
1.数据获取
餐饮外卖平台对于用户的订单、评论等信息进行收集,以JSON文件格式存放于网站的数据库(MySQL)中。将JSON文件下载到本地以进行进一步分析。
2.数据预处理
1.将存储于本地的JSON数据上传到HDFS
2.运用Spark加载原始评分数据
1 | val path="/user/Meal.json" |
3.对于评分数据进行探索与统计
1 | spark.sql("select count(*) as records from data").show() |
4.按日期分组统计数据分布
1 | val dataWithDate = spark.sql("select * ,(From_Unixtime(reviewtime,'yyyy-MM-dd')) as reviewdate from data") |
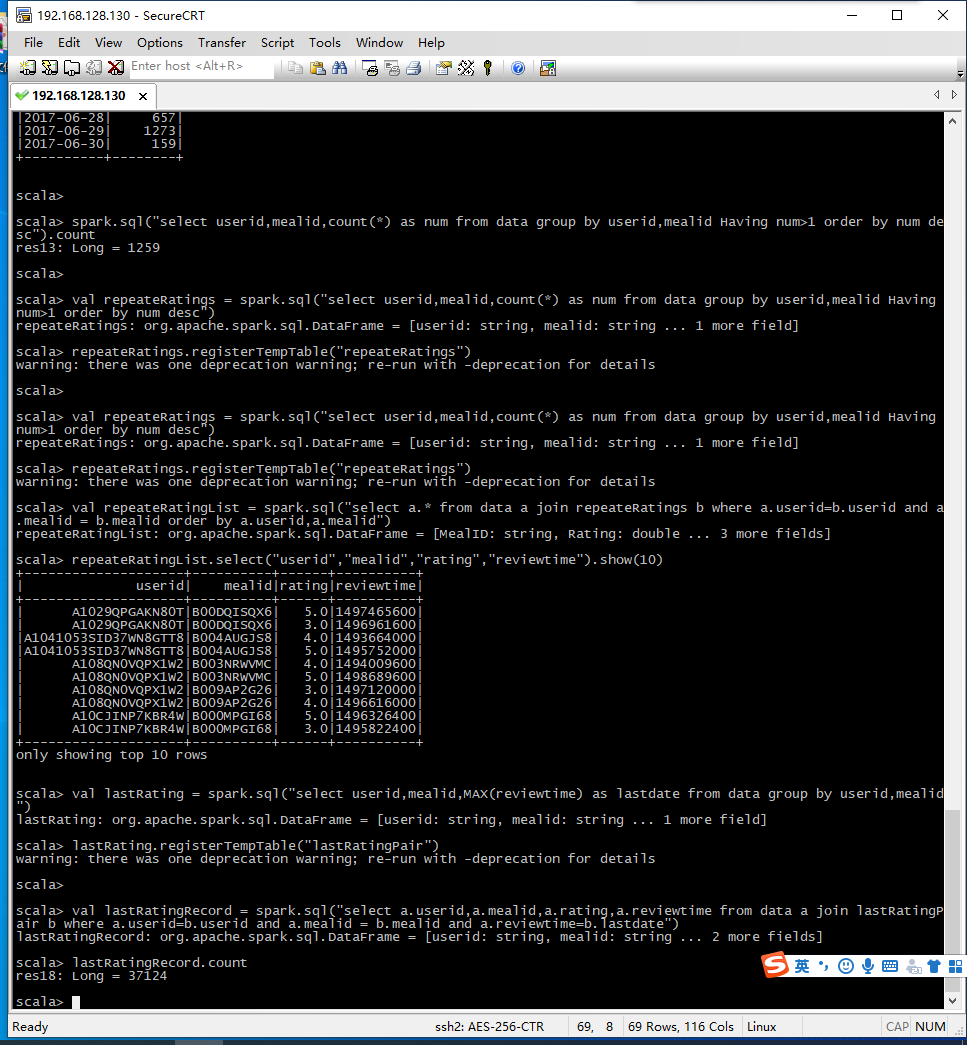
5.查询重复评分记录,最新的评分认定为菜品的最终评价。同一用户与菜品的评分只以最新的评分记录为准。通过Spark SQL对原始数据进行处理,只抽取用户对菜品的最新评分记录
1 | val lastRating = spark.sql("select userid,mealid,MAX(reviewtime) as lastdate from data group by userid,mealid") |
6.数据变化处理。对用户数据与菜品进行去重,在进行排序。使用排序后的原使用户与菜品的下标志来替代用户或菜品。使用编码后的值替换原始数据中的值。
1 | mealzipcode=ratingrdd.map(_._2).distinct.sortBy(x=>x).zipWithIndex.map(a=>(a._1,a._2.toInt)) |
7.数据集分割。将原始数据按规则分为训练集、验证集、测试机。并让他们的占比分别为80%、10%、10%
1 | val totalnum=ratingcodelist.count() |
3.算法模型
1.基于用户的协同过滤算法建模并评测
加载训练数据集,根据用户对菜品的评分向量获得用户相似度。之后匹配训练集数据生成推荐模型。将推荐结果存储在HDFS上以供后续进行模型评价。
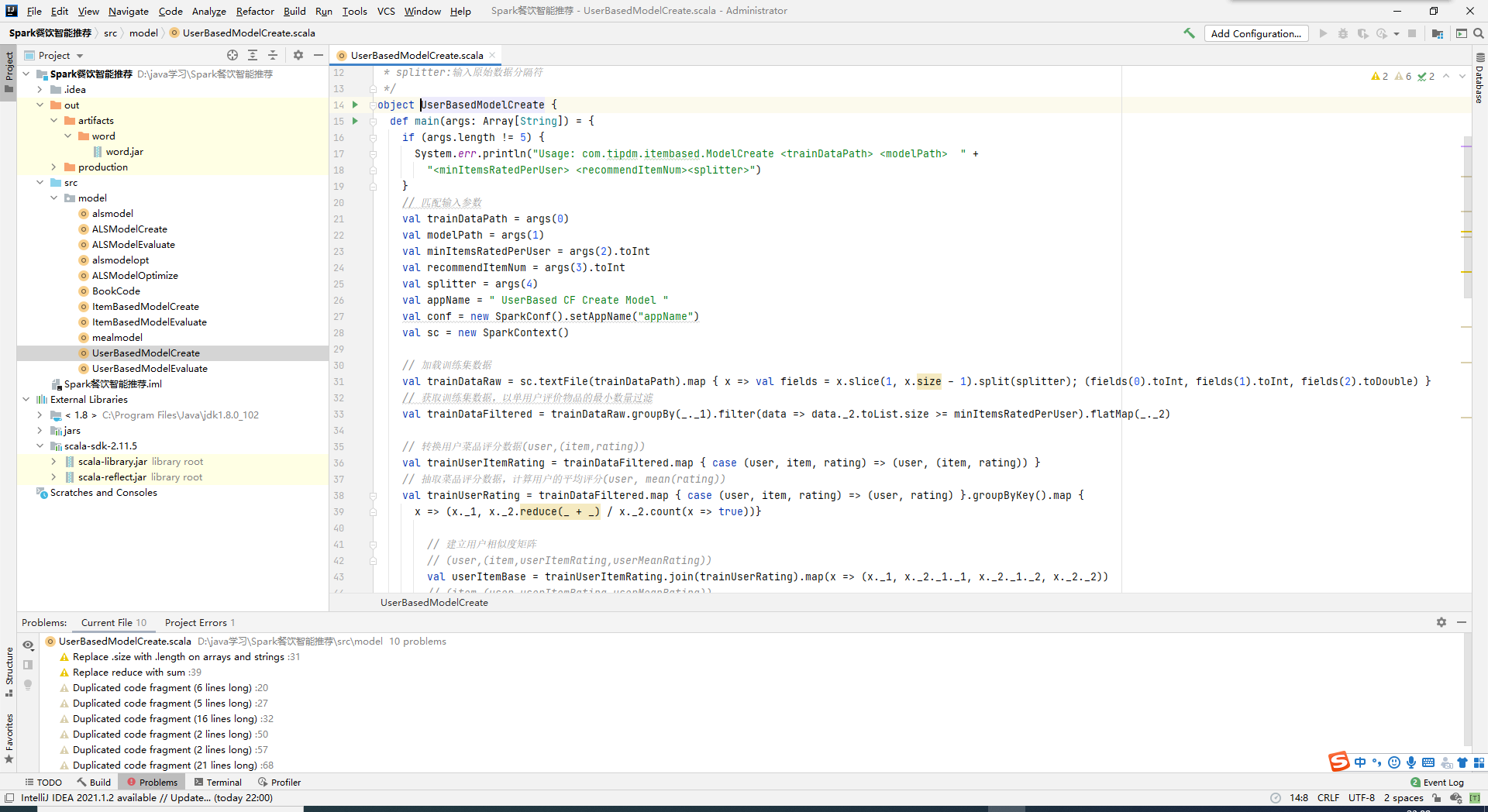
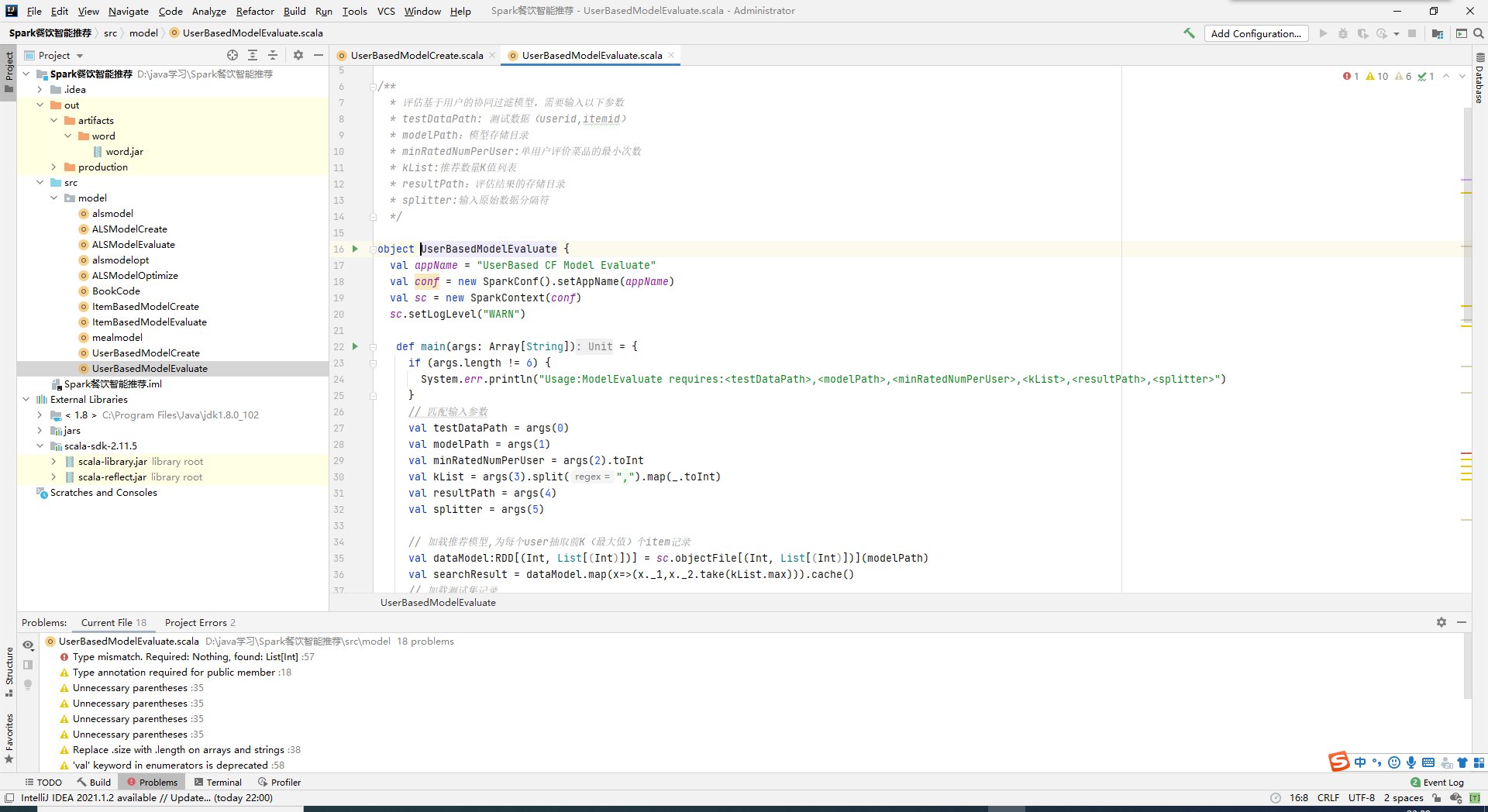
2.基于菜品的协同过滤算法建模并评测
根据用户对于某一菜品相似度最高的K个邻居物品的评分进行加权平均计算,通过评分向量获得用户相似度。匹配训练集数据生成推荐模型。将推荐结果集存储在HDFS上以供后续进行模型评价。
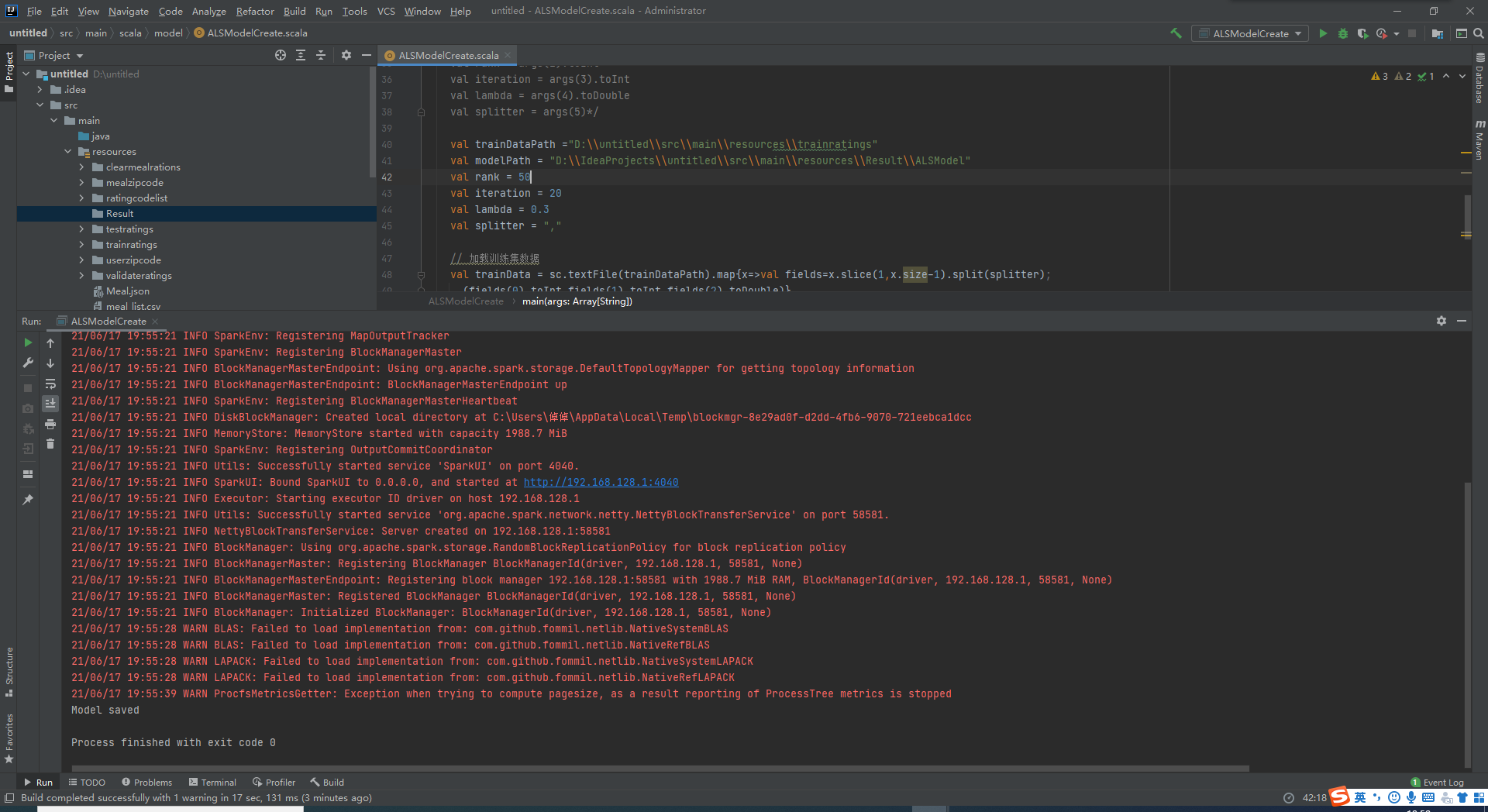
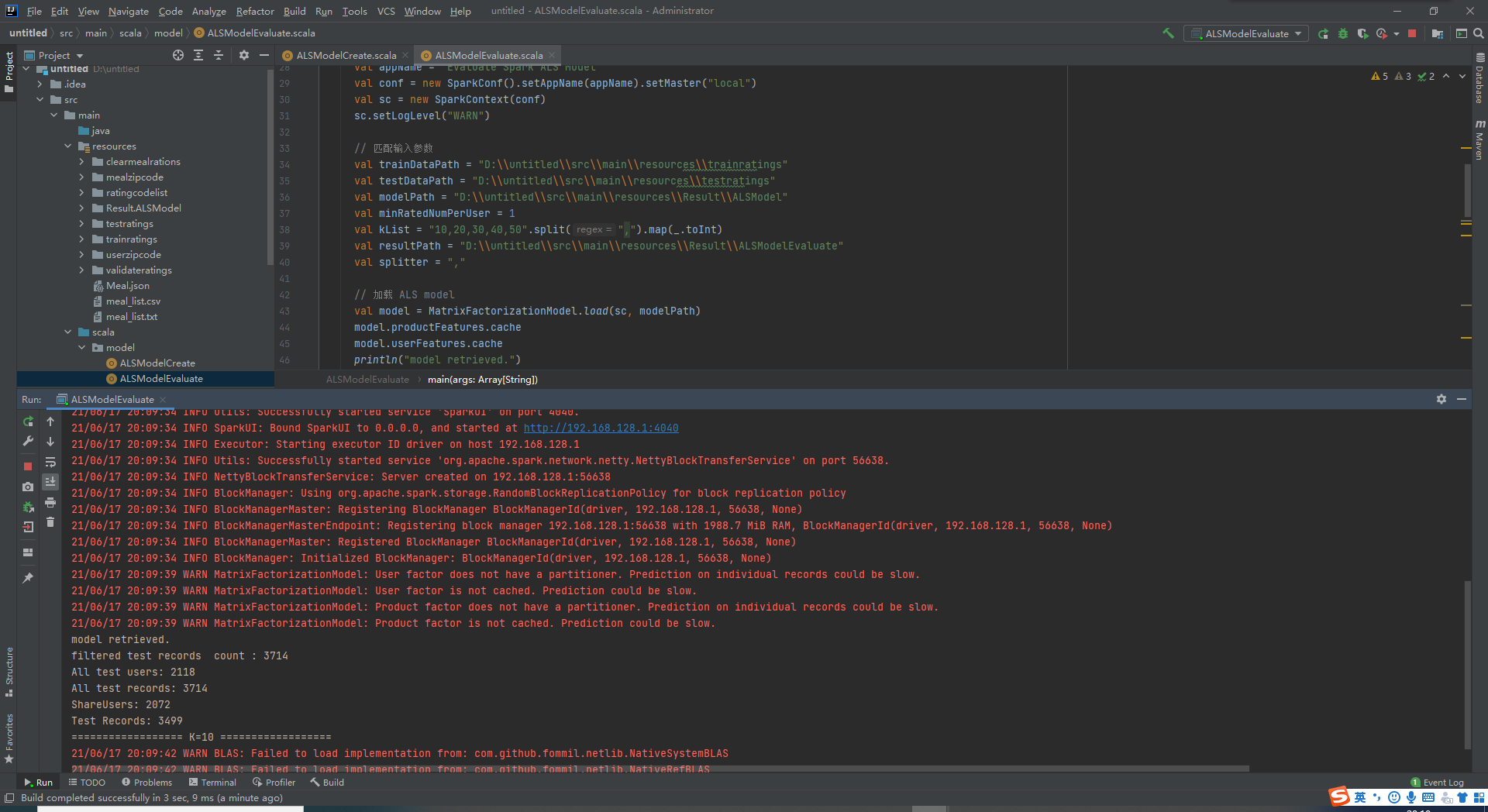
3.以基于Spak ALS算法建模并评测
Spark的Mllib包中包含ALS算法包。直接调用Spark ALS算法的train方法进行建模。Spark ALS建模需要多个参数,在参数范围中寻找一组最优的参数。使用训练集数据,输入不同组建模参数进行建模,再利用模型计算验证集中模型预测评分及实际评分的均方根差RMSE,取RMSE值最小的一组参数作为最优参数。之后使用最优参数来建模,执行Spark ALS中的train方法。
4.模型推荐
以基于菜品的推荐模型实现单用户菜品推荐
1.加载用户与菜品编码的数据集
1 | val userzipcodepath = "/user/userzipcode" |
2.读取菜品名称表
1 | val filepath = "/user/meal_list.csv" |
3.加载训练数据
1 | val traindata = sc.textFile("/user/trainratings").map{x=>val fi = x.slice(1,x.size-1).split(",");(fi(0).toInt,fi(1).toInt)} |
4.加载推荐模型
1 | import org.apache.spark.rdd.RDD |
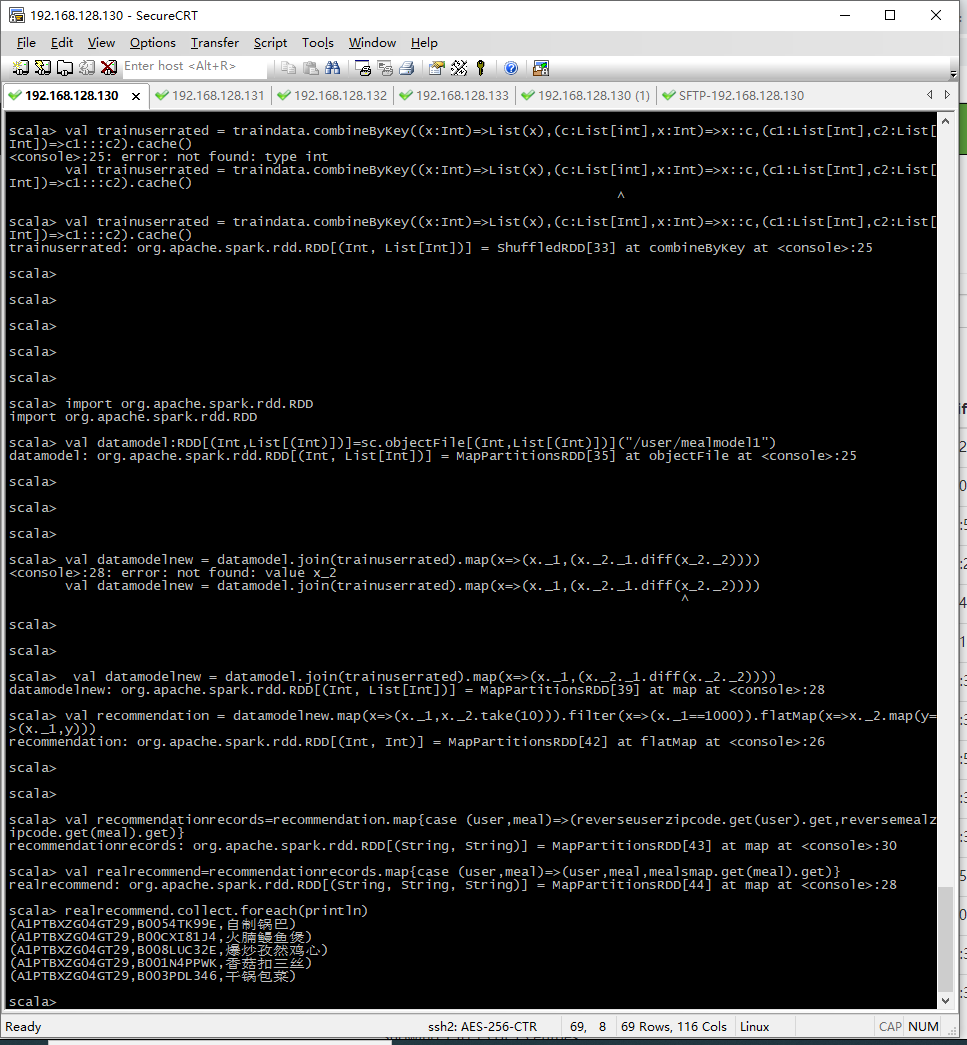
5.过滤训练数据中已有的菜品,生成可推荐的新菜品集合
1 | val datamodelnew = datamodel.join(trainuserrated).map(x=>(x._1,(x._2._1.diff(x._2._2)))) |
6.为用户推荐菜品
1 | val recommendation = datamodelnew.map(x=>(x._1,x._2.take(10))).filter(x=>(x._1==1000)).flatMap(x=>x._2.map(y=>(x._1,y))) |
四、项目实施情况参照
数据预处理
本地测试基于ALS模型
本地测试基于用户的协同过滤模型
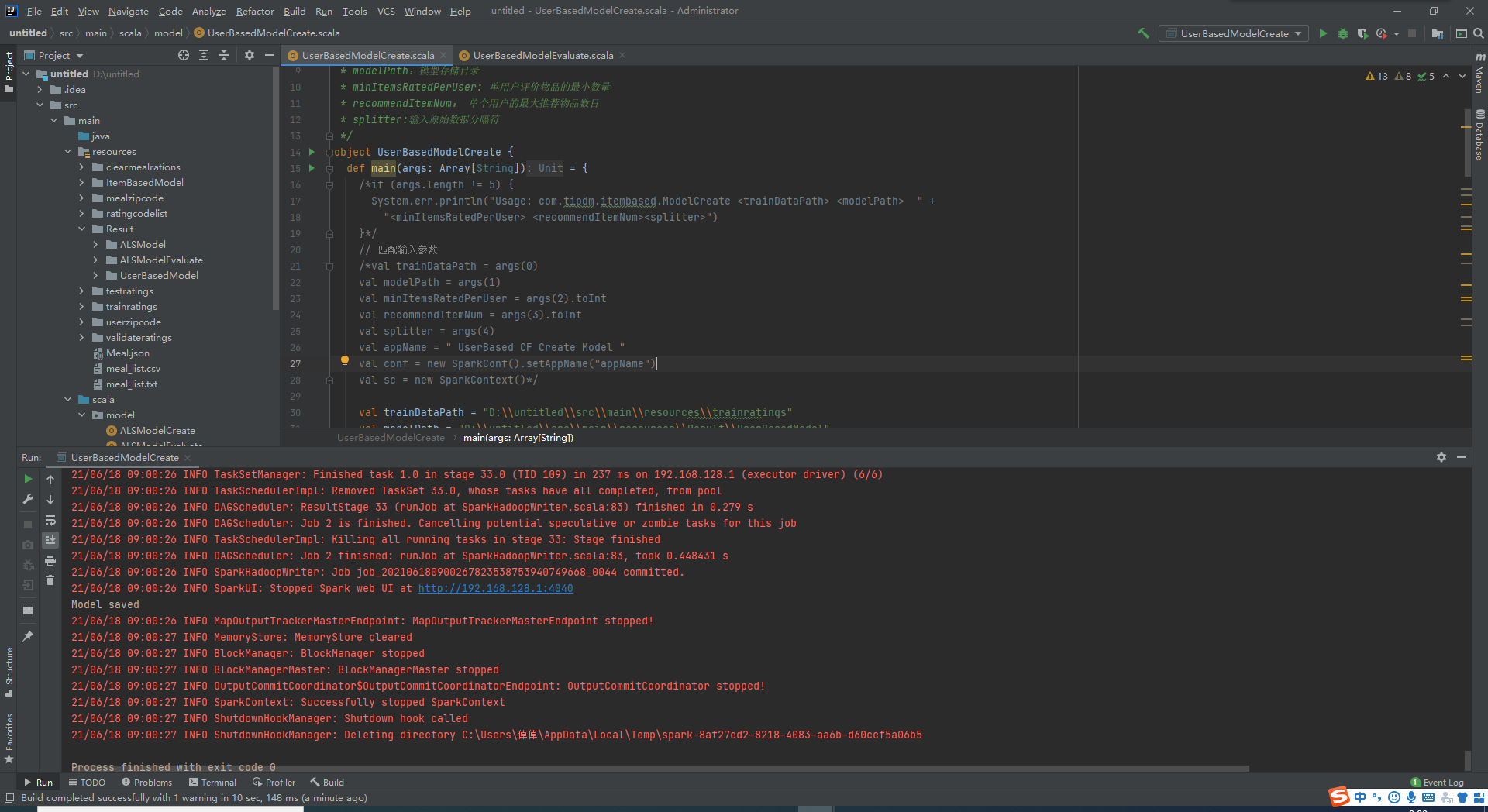
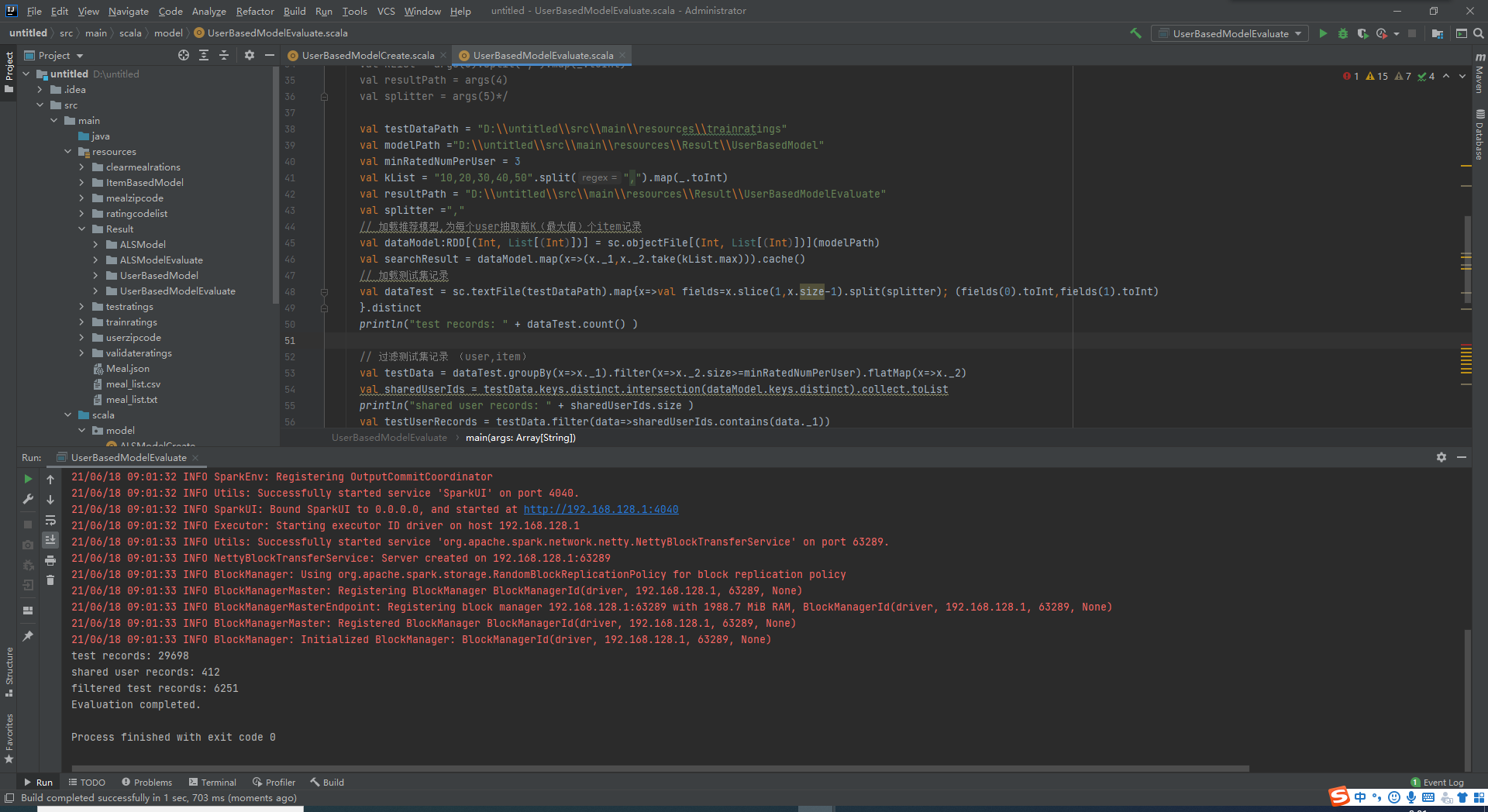
本地测试基于菜品的协同过滤模型
基于用户的协同过滤模型
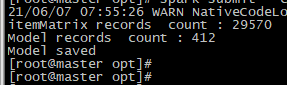
基于用户的模型评估
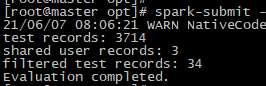
基于菜品的协同过滤模型

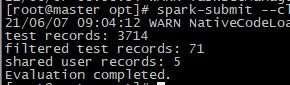
基于菜品的模型评估
加载数据
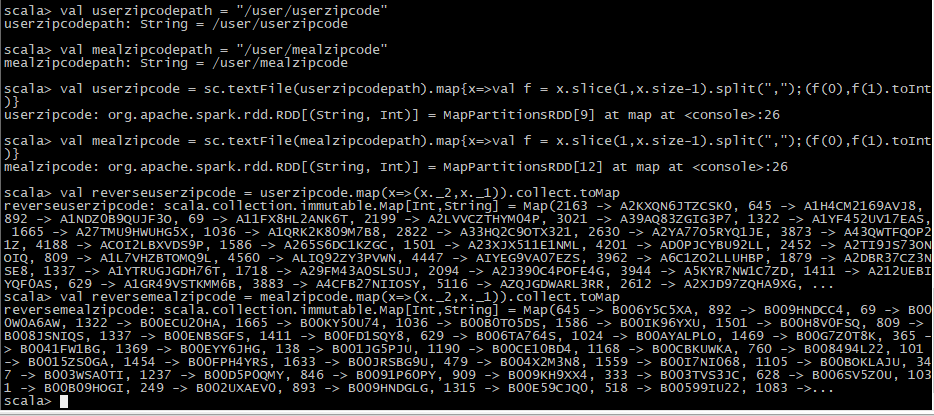
读取菜品名称表
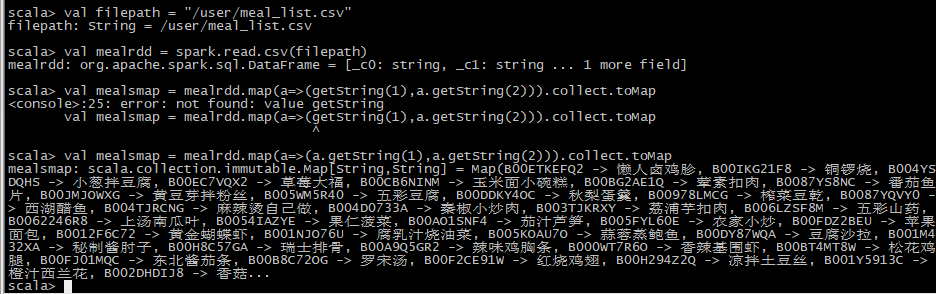
加载训练数据
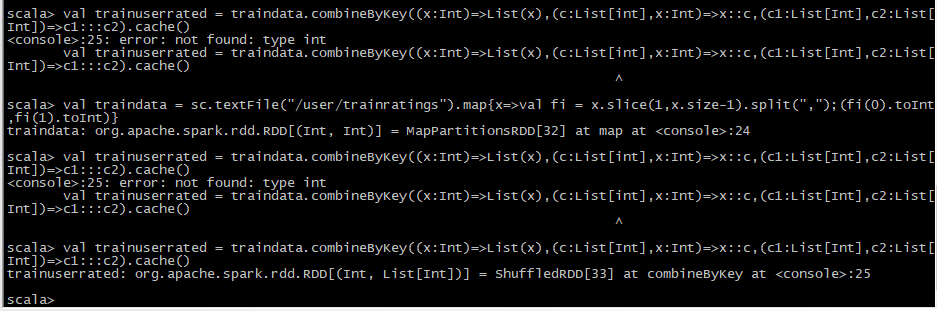
加载推荐模型

过滤训练集中的菜品,生成可推荐的新菜品集合

为用户(编码为1000)推荐菜品(userno,mealno)