objectageprocess{ defmain(args: Array[String]): Unit = { val spark = SparkSession.builder().enableHiveSupport().getOrCreate() spark.sparkContext.setLogLevel("WARN")
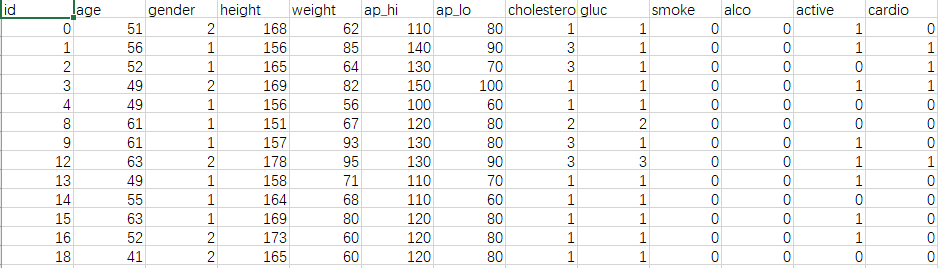
val cardio = spark.read.table("cardio.cardio")
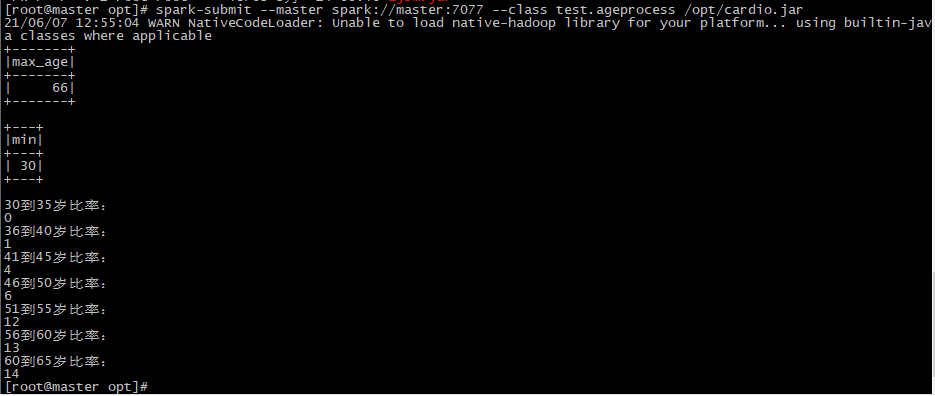
cardio.selectExpr("max(age) as max_age").show() cardio.selectExpr("min(age) as min").show()
val agetotal = cardio.select("age").count()
val age30_35 = cardio.filter("age >= '30' and age <='35'").filter("cardio = '1'").count() val result30_35 = (age30_35.toFloat/agetotal).formatted("%.2f").toFloat println("30到35岁比率:") rate(result30_35)
val age36_40 = cardio.filter("age >= '36' and age <='40'").filter("cardio = '1'").count() val result30_40 = (age36_40.toFloat/agetotal).formatted("%.2f").toFloat println("36到40岁比率:") rate(result30_40)
val age41_45 = cardio.filter("age >= '41' and age <='45'").filter("cardio = '1'").count() val result41_45 = (age41_45.toFloat/agetotal).formatted("%.2f").toFloat println("41到45岁比率:") rate(result41_45)
val age46_50 = cardio.filter("age >= '46' and age <='50'").filter("cardio = '1'").count() val result46_50 = (age46_50.toFloat/agetotal).formatted("%.2f").toFloat println("46到50岁比率:") rate(result46_50)
val age51_55 = cardio.filter("age >= '51' and age <='55'").filter("cardio = '1'").count() val result51_55 = (age51_55.toFloat/agetotal).formatted("%.2f").toFloat println("51到55岁比率:") rate(result51_55)
val age56_60 = cardio.filter("age >= '56' and age <='60'").filter("cardio = '1'").count() val result56_60 = (age56_60.toFloat/agetotal).formatted("%.2f").toFloat println("56到60岁比率:") rate(result56_60)
val age61_65 = cardio.filter("age >= '61' and age <='65'").filter("cardio = '1'").count() val result61_65 = (age61_65.toFloat/agetotal).formatted("%.2f").toFloat println("60到65岁比率:") rate(result61_65)
} defrate(x:Float):Unit ={ var per = (x * 100).toInt println(per) } }
objecthobbys{ defmain(args: Array[String]): Unit = { val spark = SparkSession.builder().enableHiveSupport().getOrCreate() spark.sparkContext.setLogLevel("WARN")
val cardio = spark.read.table("cardio.cardio")
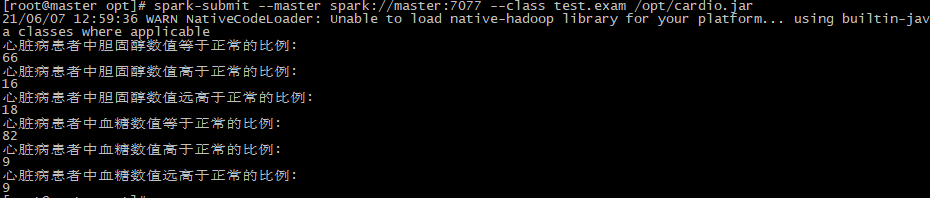
val smoke = cardio.select("smoke").filter("cardio = '1'").count() val issmoke = cardio.select("smoke").filter("smoke = '1'").filter("cardio = '1'").count() val smokeresult = (issmoke.toFloat/smoke).formatted("%.2f").toFloat println("心脏病患者中有吸烟习惯的比例:") rate(smokeresult)
val alco = cardio.select("alco").filter("cardio = '1'").count() val isalco = cardio.select("alco").filter("alco = '1'").filter("cardio = '1'").count() val alcoresult = (isalco.toFloat/alco).formatted("%.2f").toFloat println("心脏病患者中有饮酒习惯的比例:") rate(alcoresult)
val active = cardio.select("active").filter("cardio = '1'").count() val isactive = cardio.select("active").filter("active = '1'").filter("cardio = '1'").count() val activeresult = (isactive.toFloat/active).formatted("%.2f").toFloat println("心脏病患者中有锻炼习惯的比例:") rate(activeresult)
} defrate(x:Float):Unit ={ var per = (x * 100).toInt println(per) }
}
Ifcardio:
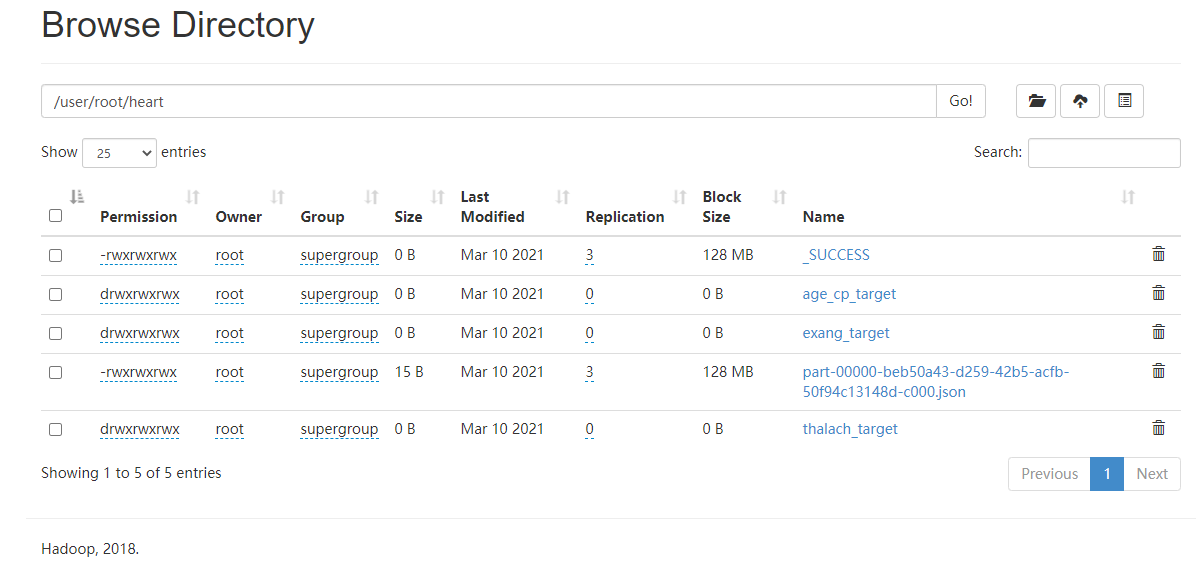
找出数据集中年龄与是否患病的信息,生成为json文件以供后续使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import org.apache.spark.sql.SparkSession
objectifcardio{ defmain(args: Array[String]): Unit = { val spark = SparkSession.builder().enableHiveSupport().getOrCreate() spark.sparkContext.setLogLevel("WARN")
val cardio = spark.read.table("cardio.cardio3")
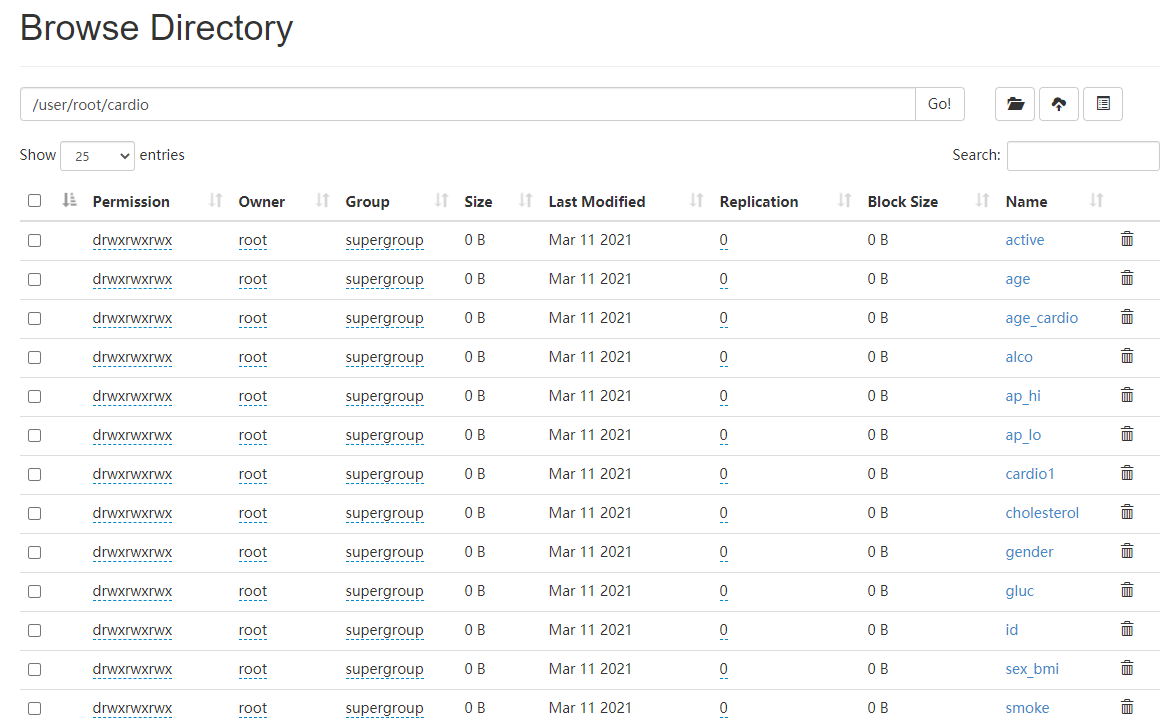
val cardio1 = cardio.select("age", "cardio") cardio1.write.mode("overwrite").json("/user/root/cardio/age_cardio") }
objectageprocess{ defmain(args: Array[String]): Unit = { val spark = SparkSession.builder().enableHiveSupport().getOrCreate() spark.sparkContext.setLogLevel("WARN")
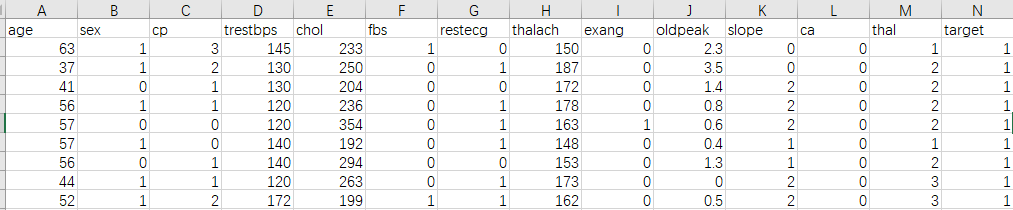
val heart = spark.read.table("heart.heart")
// val age29_40 = heart.filter("age >= '29' and age <= '40'").show() val age29_40_1 = heart.filter("age >= '29' and age <= '40'").filter("target = '1'").count() val age29_40_2 = heart.filter("age >= '29' and age <= '40'").count() val result29_40 = (age29_40_1.toFloat/age29_40_2).formatted("%.2f").toFloat println("29到40岁患病风险:") baifenshu(result29_40)
val age41_50_1 = heart.filter("age >= '41' and age <= '50'").filter("target = '1'").count() val age41_50_2 = heart.filter("age >= '41' and age <= '50'").count() val result41_50 = (age41_50_1.toFloat/age41_50_2).formatted("%.2f").toFloat println("41到50岁患病风险:") baifenshu(result41_50)
val age51_60_1 = heart.filter("age >= '51' and age <= '60'").filter("target = '1'").count() val age51_60_2 = heart.filter("age >= '51' and age <= '60'").count() val result51_60 = (age51_60_1.toFloat/age51_60_2).formatted("%.2f").toFloat println("51到60岁患病风险:") baifenshu(result51_60)
val age61_70_1 = heart.filter("age >= '61' and age <= '70'").filter("target = '1'").count() val age61_70_2 = heart.filter("age >= '61' and age <= '70'").count() val result61_70 = (age61_70_1.toFloat/age61_70_2).formatted("%.2f").toFloat println("61到70岁患病风险:") baifenshu(result61_70)
val age71_77_1 = heart.filter("age >= '71' and age <= '77'").filter("target = '1'").count() val age71_77_2 = heart.filter("age >= '71' and age <= '77'").count() val result71_77 = (age71_77_1.toFloat/age71_77_2).formatted("%.2f").toFloat println("70到71岁患病风险:") baifenshu(result71_77) }
defbaifenshu(x: Float ): Unit ={ var per = (x * 100).toInt println(per + "%") } }
Cpprocess:
选取出数据集中年龄,胸痛类型、是否患病标签写入新的json文件以供后续分析其关联
1 2 3 4 5 6 7 8 9 10 11 12 13 14
import org.apache.spark.sql.SparkSession
objectcpprocess{ defmain(args: Array[String]): Unit = { val spark = SparkSession.builder().enableHiveSupport().getOrCreate() spark.sparkContext.setLogLevel("WARN")
val heart = spark.read.table("heart.heart")
val cp = heart.select("age","cp","target") cp.write.mode("overwrite").json("/user/root/heart/age_cp_target") } }