写在最前 老早就想做的一个项目现在终于有机会开始了,Python相关技术都一段时间没用过了,这次全部记录下来随时看看O(∩_∩)O项目还没做完,慢慢更新中,希望早日完结^—^
一、相关组件
Kafka
Zookeeper
Python
Beautiful Soup
XPath
(待定……)
二、Kafka消息队列测试 启动zookeeper,默认端口为2181
1 2 3 4 /opt/software/kafka_2.12-2.7.0//bin/zookeeper-server-start.sh /opt/software/kafka_2.12-2.7.0/config/zookeeper.properties //在后台运行 /opt/software/kafka_2.12-2.7.0//bin/zookeeper-server-start.sh /opt/software/kafka_2.12-2.7.0/config/zookeeper.properties &
启动kafka,启动kafka broker服务器,broker在端口9092监听
1 /opt/software/kafka_2.12-2.7.0/bin/kafka-server-start.sh /opt/software/kafka_2.12-2.7.0/config/server.properties
创建topic
1 /opt/software/kafka_2.12-2.7.0/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic weibotop
查看topic
1 /opt/software/kafka_2.12-2.7.0/bin/kafka-topics.sh --list --zookeeper localhost:2181
运行kafka控制台生产者
1 /opt/software/kafka_2.12-2.7.0/bin/kafka-console-producer.sh --bootstrap-server localhost:9092 -topic weibotop
另起一个窗口运行控制台消费者
1 /opt/software/kafka_2.12-2.7.0/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic weibotop --from-beginning
三、Python编程连接Kafka测试 在/opt目录下新建文件: vim demo_kafka_producer.py
若出现权限问题修改权限:sudo chmod 777 /opt
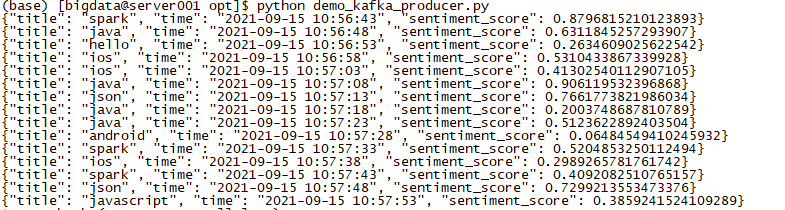
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from kafka import KafkaProducer import time import json import random #连接kafka producer = KafkaProducer(bootstrap_servers='localhost:9092',key_serializer=lambda k: json.dumps(k).encode(),value_serializer=lambda v: json.dumps(v).encode()) strings = ["hello","world","java","spark","json","javascript","scala","ios","android"] while True: #随机选择一个字符串 title = random.choice(strings) #用字典组织待发送的消息 msg = {'title':title,'time':time.strftime(r"%Y-%m-%d %H:%M:%S",time.localtime()),'sentiment_score':random.random()} #把消息转为json字符串 msg = json.dumps(msg) print(str(msg)) #发送给kafka producer.send('weibotop',key='title_sentiment_score',value=msg) time.sleep(5)
执行demo_kafka_producer.py
1 python demo_kafka_producer.py
ok,producer没问题看一下consumer
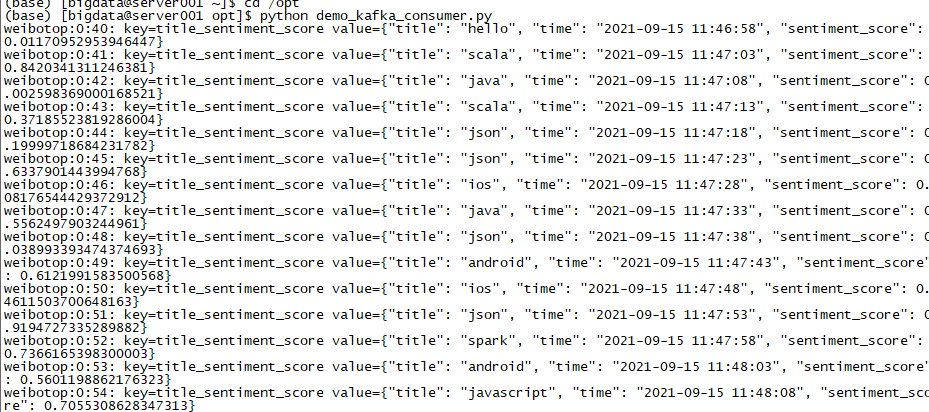
1 vim demo_kafka_consumer.py
1 2 3 4 5 6 7 8 9 10 from kafka import KafkaConsumer import time import json #连接Kafka consumer = KafkaConsumer('weibotop',bootstrap_servers=['localhost:9092']) while True: for msg in consumer: recv = "{}:{}:{}: key={} value={}".format(msg.topic, msg.partition, msg.offset, json.loads(msg.k ey.decode()), json.loads(msg.value.decode())) print(recv) time.sleep(5)
都没问题,进行下一步^_^
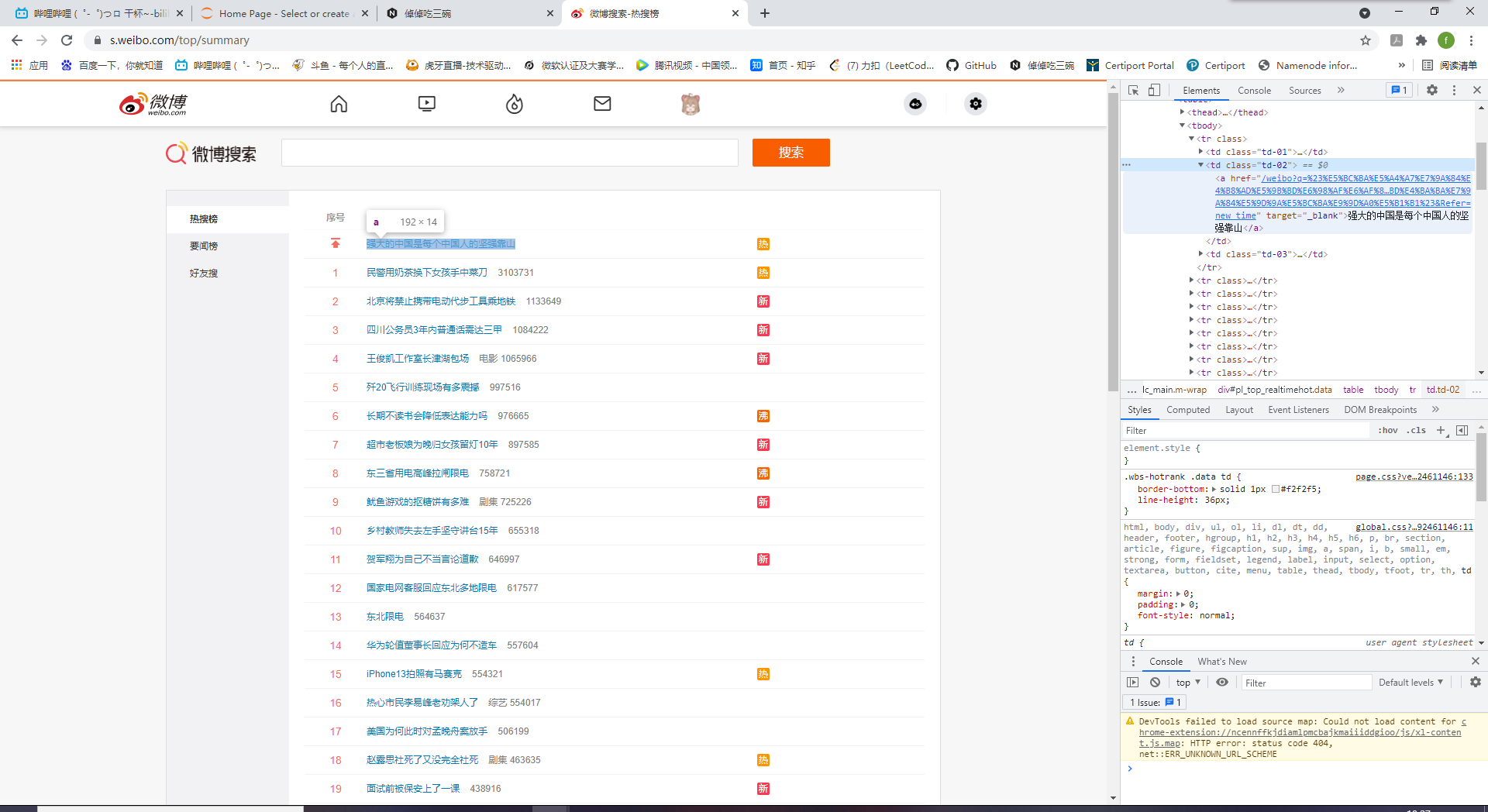
四、爬虫 4.1 requests+正则表达式 运用requests库加上正则表达式抓取内容,先来看一看网页布局
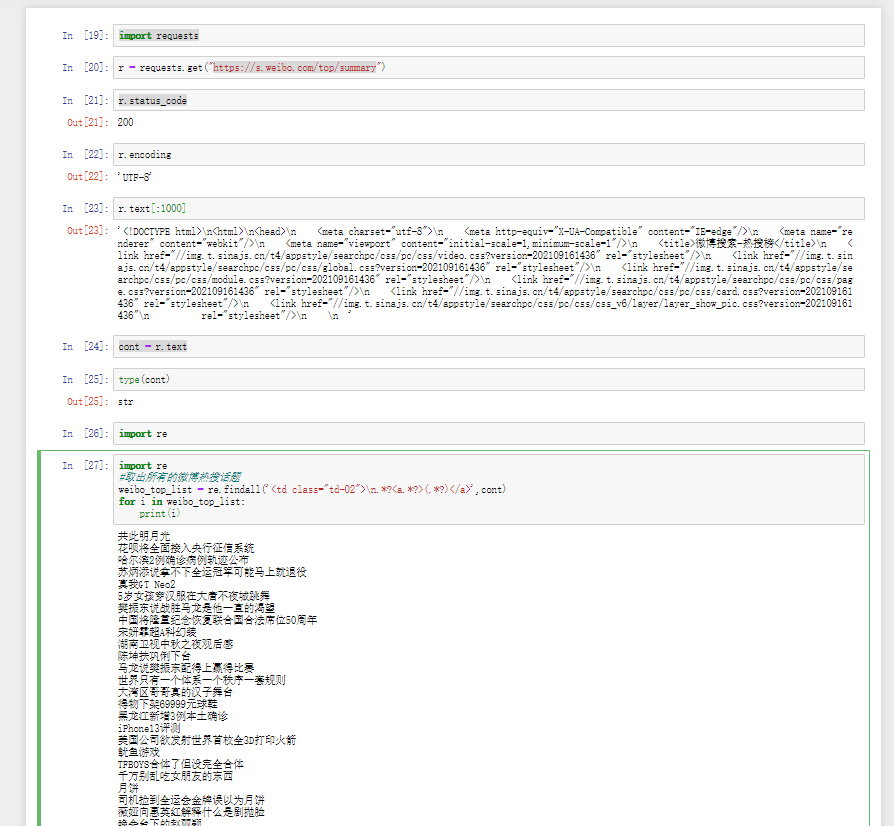
1 2 3 4 5 6 import requestsr = requests.get("https://s.weibo.com/top/summary" ) cont = r.text //cont来接一下内容
1 2 3 4 5 import reweibo_top_list = re.findall('<td class="td-02">\n.*?<a.*?>(.*?)</a>' ,cont) for i in weibo_top_list: print (i)
打印看一看:
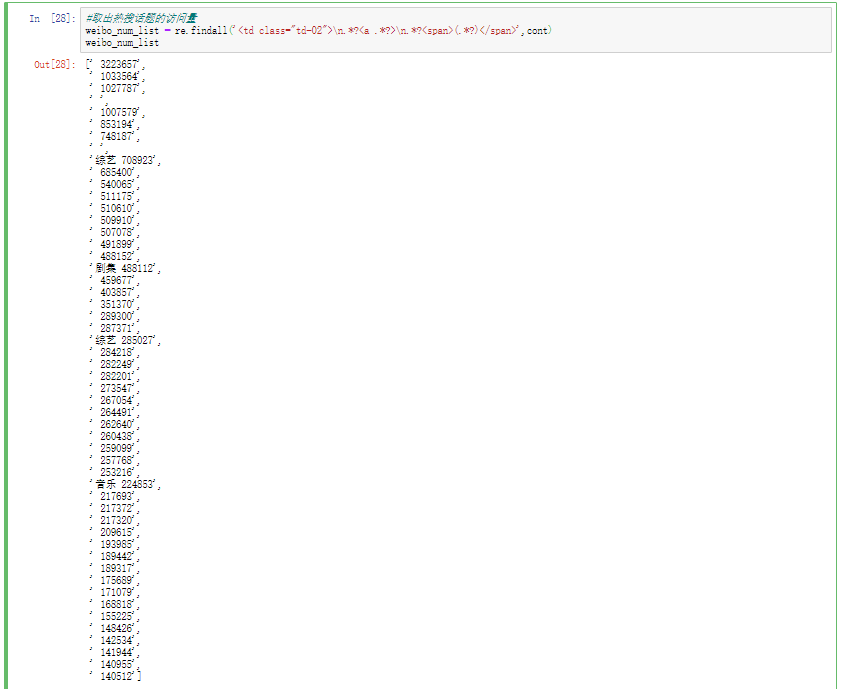
观察一下网页布局,取出热搜话题的访问量
1 2 3 weibo_num_list = re.findall('<td class="td-02">\n.*?<a .*?>\n.*?<span>(.*?)</span>' ,cont) weibo_num_list
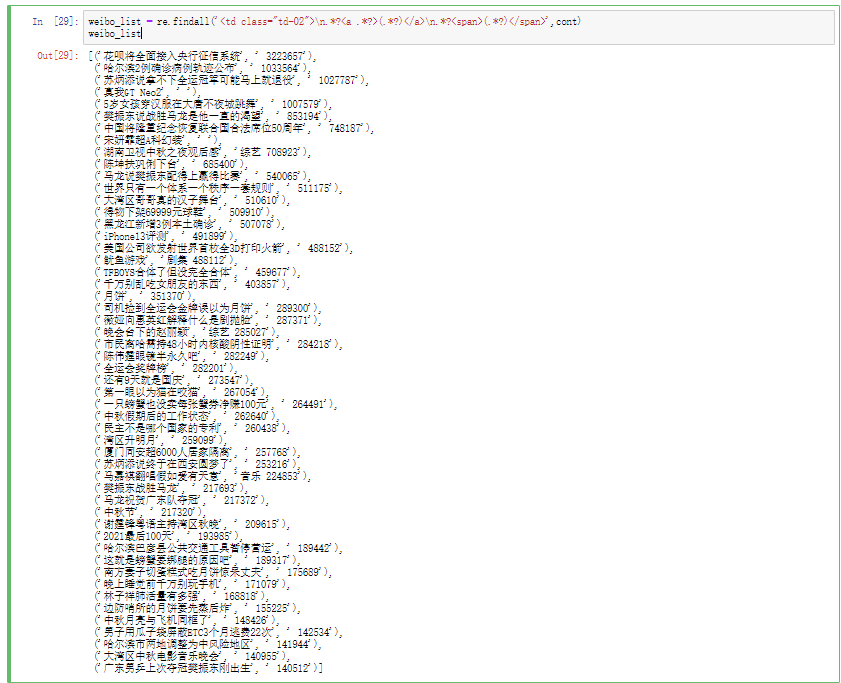
findall()方法找出话题和访问量
1 2 weibo_list = re.findall('<td class="td-02">\n.*?<a .*?>(.*?)</a>\n.*?<span>(.*?)</span>' ,cont) weibo_list
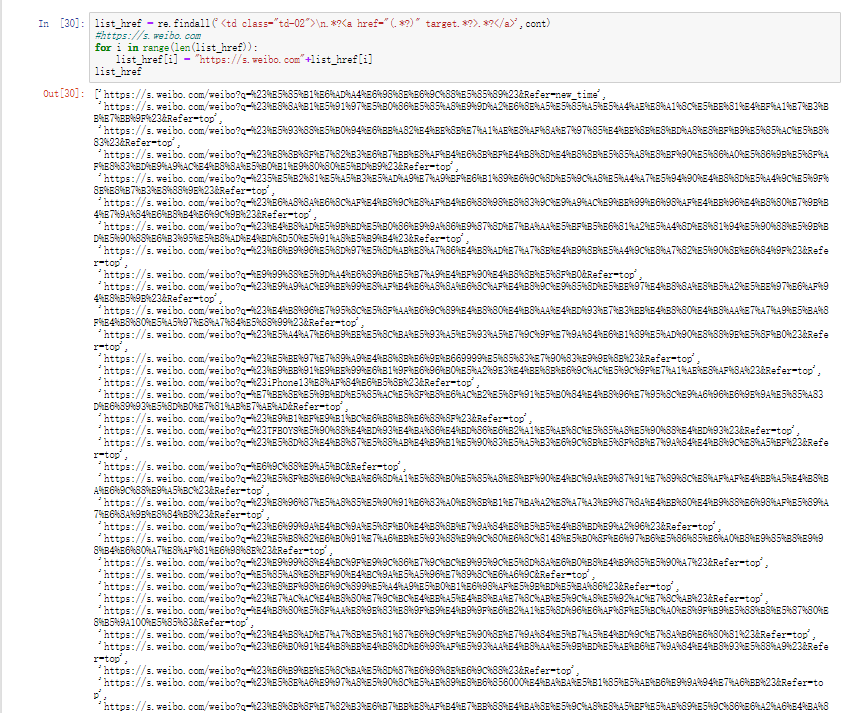
观察一下href标签里的链接,需要拼接一下
1 2 3 4 5 list_href = re.findall('<td class="td-02">\n.*?<a href="(.*?)" target.*?>.*?</a>' ,cont) for i in range (len (list_href)): list_href[i] = "https://s.weibo.com" +list_href[i] list_href
4.2 BeautifulSoup库 BeautifulSoup介绍 Beautiful Soup是python的一个HTML或XM的解析库,可以用它来方便地从网页中提取数据。Beautiful Soup在解析时实际上依赖解析器,它除了支持python标准库中的HTML解析器外,还支持一些第三方解析器(比如lxml)。下面是Beautiful Soup支持的解析器
解析器
使用方法
python标准库
BeautifulSoup(markup,”html.parser”)
lxml HTML 解析器
BeautifulSoup(markup,”lxml”)
Lxml XML 解析器
BeautifulSoup(markup,”xml”)
html5lib
BeautifulSoup(markup, “html5lib”)
先导入模块:
1 from bs4 import BeautifulSoup
(以后研究研究底层源码单独写一篇介绍^_^这里直接开用)
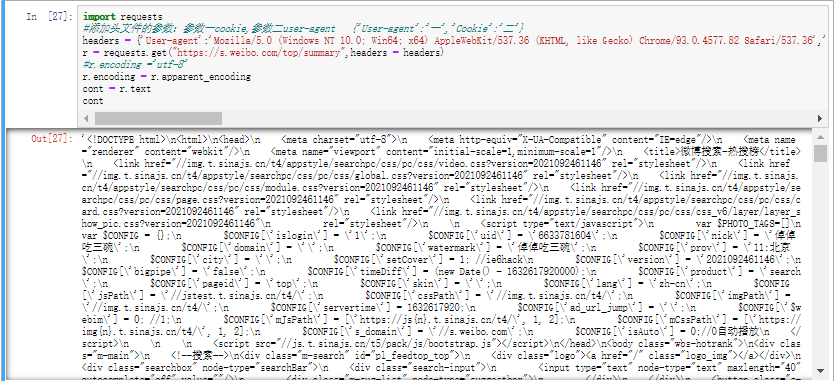
4.2.1基本使用 1 2 3 4 5 from bs4 import BeautifulSoupimport requestsr = requests.get("https://s.weibo.com/top/summary" ) r.encoding ='utf-8' html = r.text
1 2 3 soup = BeautifulSoup(html,'lxml' ) print (soup.title)print (soup.title.string)
打印效果
1 2 <title>微博搜索-热搜榜</title> 微博搜索-热搜榜
练习一下 1 2 3 4 5 6 print (soup.head.title)print (soup.title.name)print (soup.p.attrs)print (soup.p['class' ])print (soup.p.string)
4.2.2根据标签查询
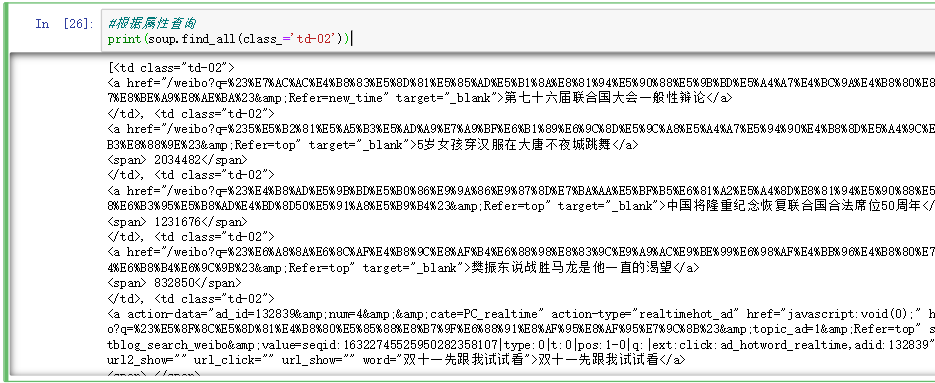
4.2.3根据属性查询 1 2 print (soup.find_all(class_='td-02' ))
4.2.4根据文本查询 1 2 print (soup.find_all(text="第七十六届联合国大会一般性辩论" ))
4.2.5返回单个元素
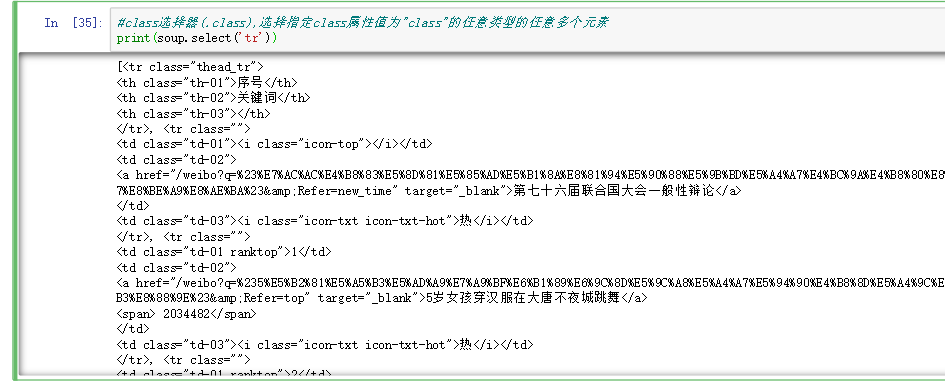
4.2.6选择器 1 2 3 print (soup.select('tr' ))
1 2 print (soup.select('tr' ))
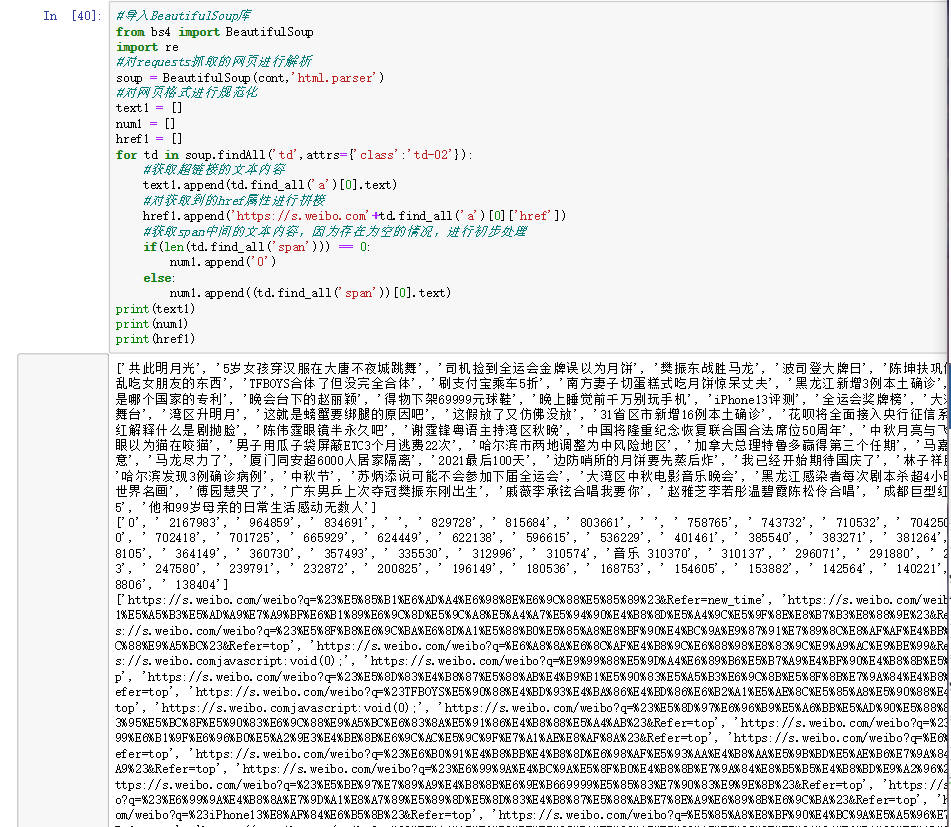
实际测试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from bs4 import BeautifulSoupimport resoup = BeautifulSoup(cont,'html.parser' ) text1 = [] num1 = [] href1 = [] for td in soup.findAll('td' ,attrs={'class' :'td-02' }): text1.append(td.find_all('a' )[0 ].text) href1.append('https://s.weibo.com' +td.find_all('a' )[0 ]['href' ]) if (len (td.find_all('span' ))) == 0 : num1.append('0' ) else : num1.append((td.find_all('span' ))[0 ].text) print (text1)print (num1)print (href1)
看看打印效果
4.3 XPath XPath介绍 XPath,全称XML Path Language,即XML路径语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索
XPath常用规则如下表:
表达式
描述
nodename
选取此节点的所有子节点
/
从当前节点选取直接子节点
//
从当前节点选取子孙节点
选取当前节点
..
选取当前节点的父节点
@
选取属性
4.2.1基本使用 前提:先用requests.get方法把网页内容抓取下来
1 2 3 4 5 6 7 8 import requestsheaders = {'User-agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36' ,'Cookie' :'SINAGLOBAL=5067277944781.756.1539012379187; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFXAgGhhYE-bL1UlBNsI6xh5JpX5KMhUgL.Foqce0eN1h2cehB2dJLoIEXLxK-L1h5LB-eLxK-L1h5LB-eLxK-L1K5L1heLxKBLBonL1h.LxKMLBKzL1KMt; UOR=jx3.xoyo.com,widget.weibo.com,login.sina.com.cn; ALF=1664153011; SSOLoginState=1632617011; SCF=AjnY75MXDIg2Sev-TVKQBdyuwLa-mrIYwFgLkjivnwGq9GaIAF5uHgYnst2gv0cRrA6x5Vsl7gF_Y_lSyh6OWlk.; SUB=_2A25MS7JhDeRhGeBI6FEW-C_KyziIHXVvIKSprDV8PUNbmtB-LRilkW9NRppHJp5FjHOZP1aqOyCcshDo3WzrSWG9; _s_tentry=weibo.com; Apache=9627509181880.607.1632617051539; ULV=1632617051630:44:5:1:9627509181880.607.1632617051539:1632443880062; WBStorage=6ff1c79b|undefined' } r = requests.get("https://s.weibo.com/top/summary" ,headers = headers) r.encoding = r.apparent_encoding cont = r.text cont
1.导入etree库
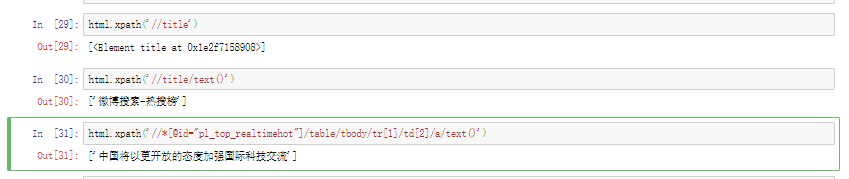
1 2 3 4 5 from lxml import etreehtml = etree.HTML(cont) print (html.xpath('//tbody/tr/td[2]/a/text()' ))print (html.xpath('//tbody/tr/td[2]/a/@href' ))print (html.xpath('//tbody/tr/td[2]/span/text()' ))
4.2.2 练习看一看 1 2 3 4 5 html.xpath('//title' ) html.xpath('//title/text()' ) html.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr[1]/td[2]/a/text()' )
五、数据处理与特征提取 5.1去除噪声 用户名、URL链接、引用等都属于噪声数据,对于训练模型可能会产生干扰。比如“@努力加油”这样的用户名会对词性特征造成影响
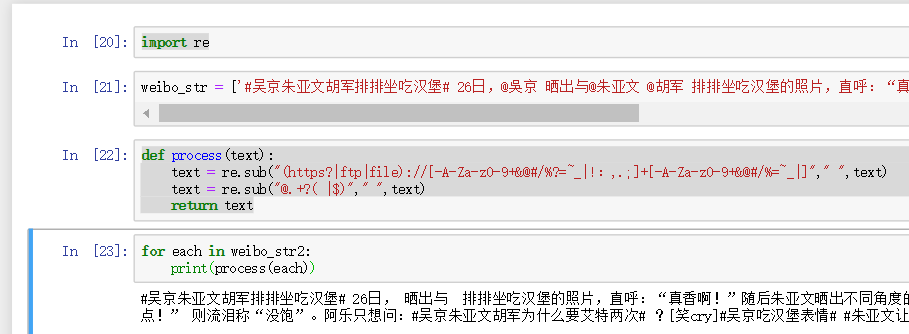
运用python正则表达库re来删除噪声数据
1 2 3 4 5 6 7 8 9 10 import reweibo_str = ['#吴京朱亚文胡军排排坐吃汉堡# 26日,@吳京 晒出与@朱亚文 @胡军 排排坐吃汉堡的照片,直呼:“真香啊!”随后朱亚文晒出不同角度的照片,喊话被汉堡噎住的吴京:“吃慢点!”@胡军 则流泪称“没饱”。阿乐只想问:#吴京朱亚文胡军为什么要艾特两次# ?[笑cry]#吴京吃汉堡表情# #朱亚文让吴京吃慢点# ' ] def process (text ): text = re.sub("(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]" ," " ,text) text = re.sub("@.+?( |$)" ," " ,text) return text for each in weibo_str2: print (process(each))
‘@用户名’被去掉了,成功
5.2分词 jieba库支持中文分词、开源、非常强大。它有以下三种模式:
精确模式:把文本精确的切分开,不存在冗余单词
全模式:把文本中所有可能的词语都扫描出来,有冗余
搜索引擎模式:在精确模式基础上,对长词再次切分
底层源码很精妙,直接用起来更是简单安逸:
1 2 3 4 5 6 7 8 import jiebastrs = ["人们总是在不停地改变自己的内心" ,"最后的获胜者将会彻底失去他的灵魂" ,"所以我不会去改变自己" ] jieba_result = [] for each in strs: print (jieba.lcut(each,cut_all=True )) print (jieba.lcut(each,cut_all=False )) jieba_result.append(jieba.lcut(each,cut_all = True ))