写在最前 爬虫相关内容的阶段性成果。爬虫技术应用广泛,但若只是爬取到数据而不加以分析那么数据终究只是一堆数据而已,本项目将微博热搜内容爬取后进行情感分析。旨在对于爬虫技术以及数据分析技术进行探索学习^_^
总体流程 (1)数据爬取和处理 1.爬取“吴磊绝杀”对应的微博主要内容cont,对应函数get_weibo_list(url)
2.对爬取到的微博主要内容调用process(test)函数去噪和分词,得到处理后的结果pro_cont
3.将pro_cont转为DataFrame格式,为转为文本向量做准备
4.加载停用词
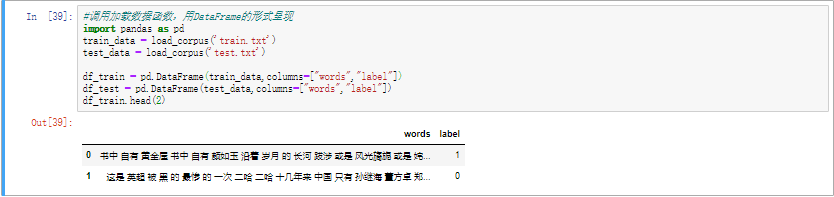
(2)构建分类模型 1.加载训练集train.txt和测试集test.txt语料库
2.定义训练样本数据
3.构建朴素贝叶斯分类模型
4.测试集数据集检验准确度
5.保存模型
(3)应用模型 1.对指定标题的微博主要内容运用模型预测情绪
项目源代码:https://github.com/zhuozhuo233/weibotop-emotional-analysis/tree/main
一、数据爬取 先观察一下页面结构
爬取内容函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import requestsimport jsonfrom lxml import etreefrom bs4 import BeautifulSoupheaders={ 'Cookie' :'SINAGLOBAL=5067277944781.756.1539012379187; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFXAgGhhYE-bL1UlBNsI6xh5JpX5KMhUgL.Foqce0eN1h2cehB2dJLoIEXLxK-L1h5LB-eLxK-L1h5LB-eLxK-L1K5L1heLxKBLBonL1h.LxKMLBKzL1KMt; UOR=jx3.xoyo.com,widget.weibo.com,login.sina.com.cn; ALF=1665190926; SSOLoginState=1633654926; SCF=AjnY75MXDIg2Sev-TVKQBdyuwLa-mrIYwFgLkjivnwGqe4HMR8MVkSqyfw315Fic7gc1c38G1W-RUtxrwPqe0qY.; SUB=_2A25MW-jeDeRhGeBI6FEW-C_KyziIHXVvEV0WrDV8PUNbmtAKLUzhkW9NRppHJg76K77LtSOxPlpC13YygxcK3EKM; _s_tentry=login.sina.com.cn; Apache=441836365226.03375.1633654927612; ULV=1633654927618:48:1:1:441836365226.03375.1633654927612:1632876696485' , 'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36' } def get_weibo_list (url ): r = requests.get(url,headers=headers) bs = BeautifulSoup(r.text) body = bs.body div_m_main = body.find('div' ,attrs={'class' :'m-main' }) div_m_wrap = div_m_main.find('div' ,attrs={'class' :'m-wrap' }) div_m_con_l = div_m_wrap.find('div' ,attrs={'class' :'m-con-l' }) data_div = div_m_con_l.findAll('div' ,attrs={'class' :'card-wrap' ,'action-type' :'feed_list_item' }) weibo_list = [] for each_div in data_div: div_card = each_div.find('div' ,attrs={'class' :'card' }) div_card_feed = div_card.find('div' ,attrs={'class' :'card-feed' }) div_content = div_card_feed.find('div' ,attrs={'class' :'content' }) p_feed_list_content = div_content.find('p' ,attrs={'class' :'txt' ,'node-type' :'feed_list_content' }) content_text = p_feed_list_content.get_text() p_feed_list_content_full = div_content.find('p' ,attrs={'class' :'txt' ,'node-type' :'feed_list_content_full' }) if p_feed_list_content_full: content_text = p_feed_list_content_full.get_text() weibo_list.append(content_text.strip()) return weibo_list
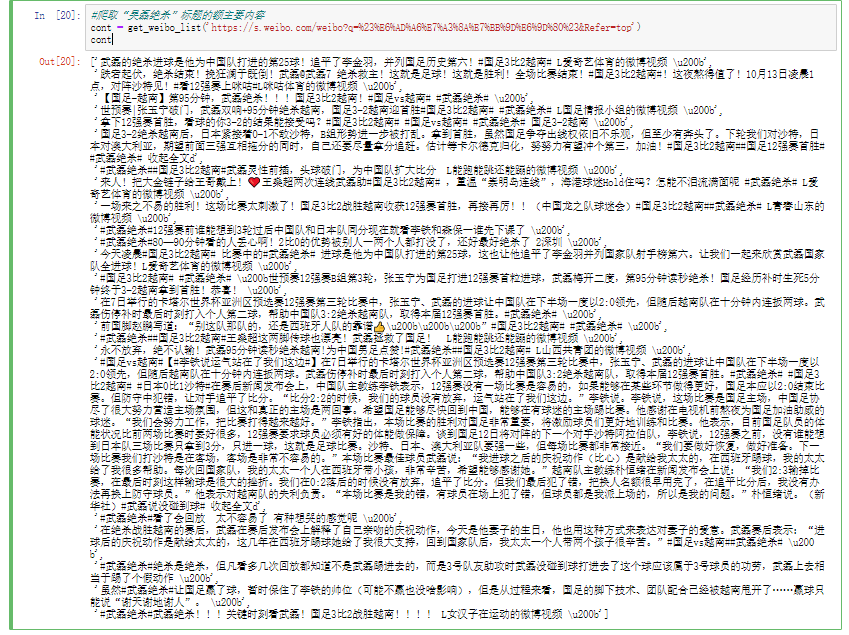
爬取“吴磊绝杀”标题的主要内容
1 2 cont = get_weibo_list('https://s.weibo.com/weibo?q=%23%E6%AD%A6%E7%A3%8A%E7%BB%9D%E6%9D%80%23&Refer=top' ) cont
去噪函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import reimport jiebadef process (text ): text = re.sub("(https?|ftp|file)://[-A-Za-z0-9+&@#/%=~_|]" ," " ,text) text = re.sub("@.+?( |$)" , " " , text) text = re.sub("\{%.+?%\}" , " " ,text) text = re.sub("\{#.+?#\}" , " " , text) text = re.sub("【.+?】" , " " , text) text = re.sub('\u200b' ," " ,text) words = [w for w in jieba.lcut(text) if w.isalpha()] result = " " .join(words) return result
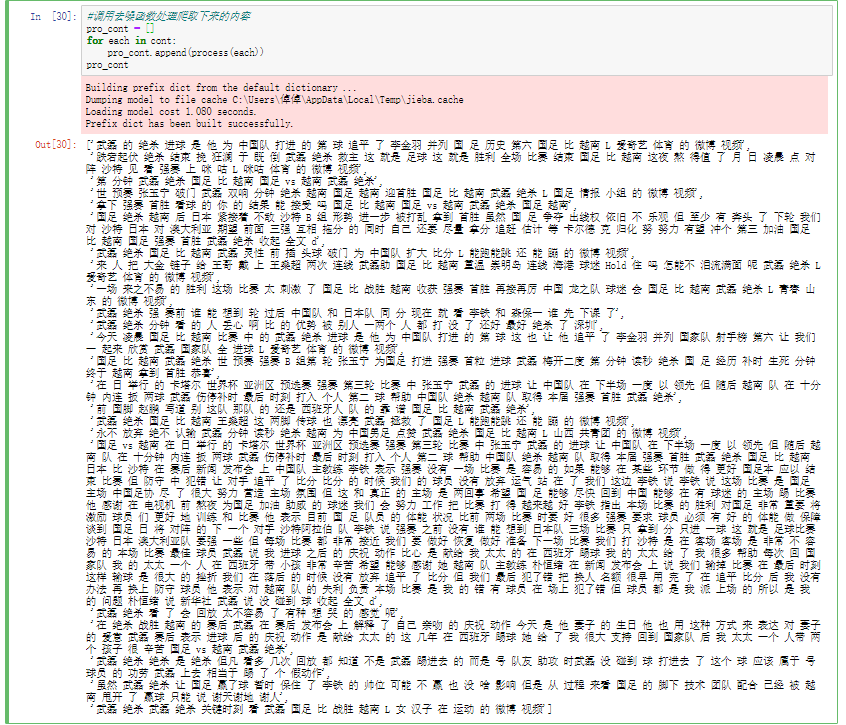
调用去噪函数处理数据
1 2 3 4 5 pro_cont = [] for each in cont: pro_cont.append(process(each)) pro_cont
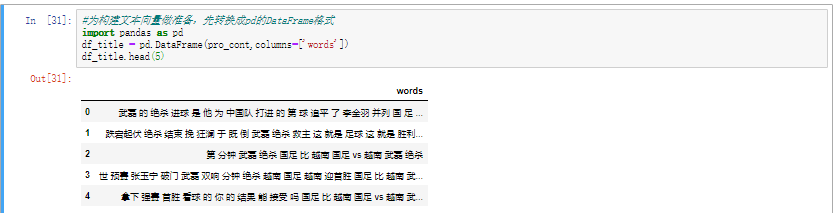
将去噪后的数据转换为DataFrame格式
1 2 3 4 import pandas as pddf_title = pd.DataFrame(pro_cont,columns=['words' ]) df_title.head(5 )
加载停用词
1 2 3 4 5 6 stopwords = [] with open ('stopwords.txt' ,'r' ,encoding='utf-8' ) as f: for w in f: stopwords.append(w.strip()) stopwords
二、构建分类模型 定义训练样本数据,训练样本数据为用逗号隔开的,字段含义为:id,情绪值,微博内容
朴素贝叶斯基础思想:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别
通俗理解便是用到DataFrame形式,将我们的内容进行结构化拆分来对分词进行判断
加载数据函数
1 2 3 4 5 6 7 8 9 10 def load_corpus (path ): data = [] with open (path,'r' ,encoding='utf8' ) as f: for line in f: [_,sentiment,content] = line.split(',' ,2 ) content = process(content) data.append((content,int (sentiment))) return data
以DataFrame形式呈现训练集与测试集
1 2 3 4 5 6 7 8 import pandas as pdtrain_data = load_corpus('train.txt' ) test_data = load_corpus('test.txt' ) df_train = pd.DataFrame(train_data,columns=["words" ,"label" ]) df_test = pd.DataFrame(test_data,columns=["words" ,"label" ]) df_train.head(2 )
用词袋模型构建训练数据的文本向量
1 2 3 4 5 6 from sklearn.feature_extraction.text import CountVectorizervectorizer = CountVectorizer(token_pattern='\[?\w+\]?' ,stop_words=stopwords) X_train = vectorizer.fit_transform(df_train["words" ]) y_train = df_train["label" ] print (type (X_train),X_train.shape)
1 2 3 X_test = vectorizer.transform(df_test["words" ]) y_test = df_test["label" ]
导入多项式朴素贝叶斯
MultinomialNB实现对多项式分布数据的朴素贝叶斯算法
1 2 3 4 5 6 from sklearn.naive_bayes import MultinomialNBclf = MultinomialNB() clf.fit(X_train,y_train)
在测试集上用模型预测结果
1 2 3 y_pred = clf.predict(X_test) print (y_pred)
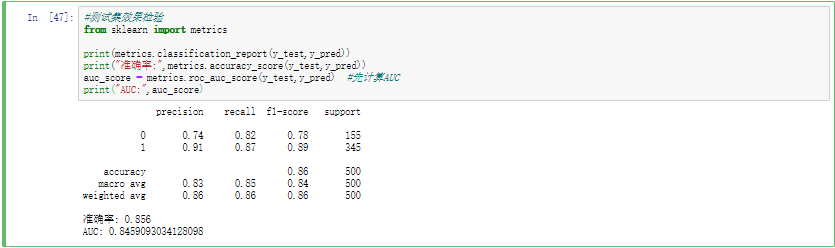
准确度检验
1 2 3 4 5 6 7 from sklearn import metricsprint (metrics.classification_report(y_test,y_pred))print ("准确率:" ,metrics.accuracy_score(y_test,y_pred))auc_score = metrics.roc_auc_score(y_test,y_pred) print ("AUC:" ,auc_score)
保存模型
三、应用模型 1 2 3 4 5 6 7 8 9 10 x = vectorizer.transform(df_title['words' ]) y_title = clf.predict(x) import numpy as nptitle = "吴磊绝杀" print (title,'情感平均得分为:' ,np.mean(y_title))
平均得分0.8,算是很趋近于1了。中国队这次不用退钱了,看来大家都蛮高兴的: )
用pickle模块保存MultinomiaNB模型
1 2 3 4 import picklewith open ('./mnb_model.pkl' ,'wb' ) as f: pickle.dump(clf,f)
用保存的模型再测试一下
1 2 3 4 5 6 7 8 9 with open ('./mnb_model.pkl' ,'rb' ) as f: save_clf = pickle.load(f) save_clf.predict(x) import numpy as nptitle = "吴磊绝杀" print (title,'情感平均得分为:' ,np.mean(y_title))
没有问题,爬虫技术的初步探索阶段性成功^_^