一、项目开发目的 随着互联网信息技术高速发展,近年来网络上的数据可以说是爆炸式增长。如果这这些数据能够被科学地收集起来进行分析,那么对于政府、企业都可以以网络舆情为参考制定自己下一步的战略规划。具体而言,对于政府来说,通过对微博内容进行分析可以进一步了解大众,把握社会舆情风向。针对各种社会风气进行或提倡或批评的指导。对于企业来说,通过对微博内容进行分析可以快速进行用户调研,比起传统的问卷调研来说有着无与伦比的优势,并且还可以监控竞品公司舆情,以此做出全方位的分析并改善自己的产品。
新浪微博上涵盖的信息大到国家战略层面的指示,小到生活中人们的鸡毛琐事。面对这海量数据,针对微博热搜榜进行分析就可以极大程度上缩小数据量,提高对于舆论热点把握的精确性。本项目旨在爬取微博热搜正文及内容,利用贝叶斯算法对于每一条评论文本进行情绪分析,最后可视化呈现情绪评分。实现了对于微博热搜条目的可视化情感分析,以供快速理解舆情。同时,本项目也可以扩展到专门针对特定商品或政策进行情感分析,助力政企直观了解舆情,为下一步的发展提供重要参考。
基于此社会背景及需求,本项目在舆情分析方面做出一小步探索。将爬虫、数据处理、kafka架构、贝叶斯算法建模、pyecharts可视化、flask框架整合运用。作为阶段性总结在此将项目流程以此笔记记录下来。
工程文件:https://github.com/zhuozhuo233/weibotop_sentiment_analysis
二、项目开发环境 1.总体环境 项目的总体环境依托于linux系统虚拟机,虚拟机的网络IP地址为192.168.91.30,关闭防火墙避免网络无法访问与远程连接不受阻碍。Jdk版本为jdk1.8.0_212。Kafka版本为kafka_2.12-2.70。spark版本为spark-3.0.2。hadoop版本为hadoop3.2。语言为Python3.
Kafka的特性为高吞吐量、低延迟、可扩展性、持久性、可靠性、容错性、高并发。Zookeeper是分布式程序协调服务,为分布式应用提供一致性服务,其功能包括:分布式同步、组服务、域名服务、配置维护等。整个Kafka架构对应一个zookeeper集群,zookeeper用于协调不同Broker之间的关系,通过zookeeper管理集群配置,选举leader,以及在consumer group发生变化时进行rebalance。本项目设置的topic为weibotop,Producer消息生产者往Broker消息代理中所指定的topic中写消息,Consumer消息消费者从Broker消息代理中指定的topic中读取消息,Broker就是在Producer和Consumer中间起到代理保存消息的中转站作用,一个Kafka服务器节点就是一个Broker,一个或多个Broker可以组成一个Kafka集群。
2.数据获取模块 组件:python urllib包、python re包、python bs4包。
urllib包使用了request模块用于模拟HTTP发送请求,error模块进行一场处理,parse工具模块进行url处理解析,robotparser协议识别网站的robot.txt,判断是否可爬。
re包主要通过正则表达式匹配处理字符串。
bs4包主要是用了其Beautiful Soup。它除了支持python标准库中的HTML解析器外还支持lxml HTML解析器、lxml XML解析器、html5lib解析器。
3.数据预处理模块 组件:python re包、jieba分词、bag of words词袋模型。
微博内容常常带有许多噪声数据,包括对于其他用户的引用,URL链接等数据。这些噪声对训练模型无益并且可能会产生干扰,需要将其去除使模型的预测更加精确。
Jieba分词是一款Github上的开源中文分词工具,提供了多种语言接口,能够识别繁简汉字。
Bow词袋模型最早出现在自然语言处理和信息检索领域。该模型忽略文本的语法和语序,仅将其看做是若干个词汇的集合。将文本映射成一个词的向量,向量长度就是词典的大小,向量中每一个位置表示词典中的一个词,向量中的每一位上的数值表示该词在文本中出现的次数。
4.情感分析算法模块 组件:python sklearn机器学习库、python pandas包、python pickle包
Sklearn机器学习库中内置了贝叶斯模型。贝叶斯方法是一个历史悠久,有着坚实基础的机器学习方法,很多高级自然语言处理模型也能够从它演化而来。
Pandas库建立于Numpy库之上,用于数据操纵和分析。
Pickle包用于对文件进行操作。
5.可视化模块 组件:pyecharts、python flask web服务器
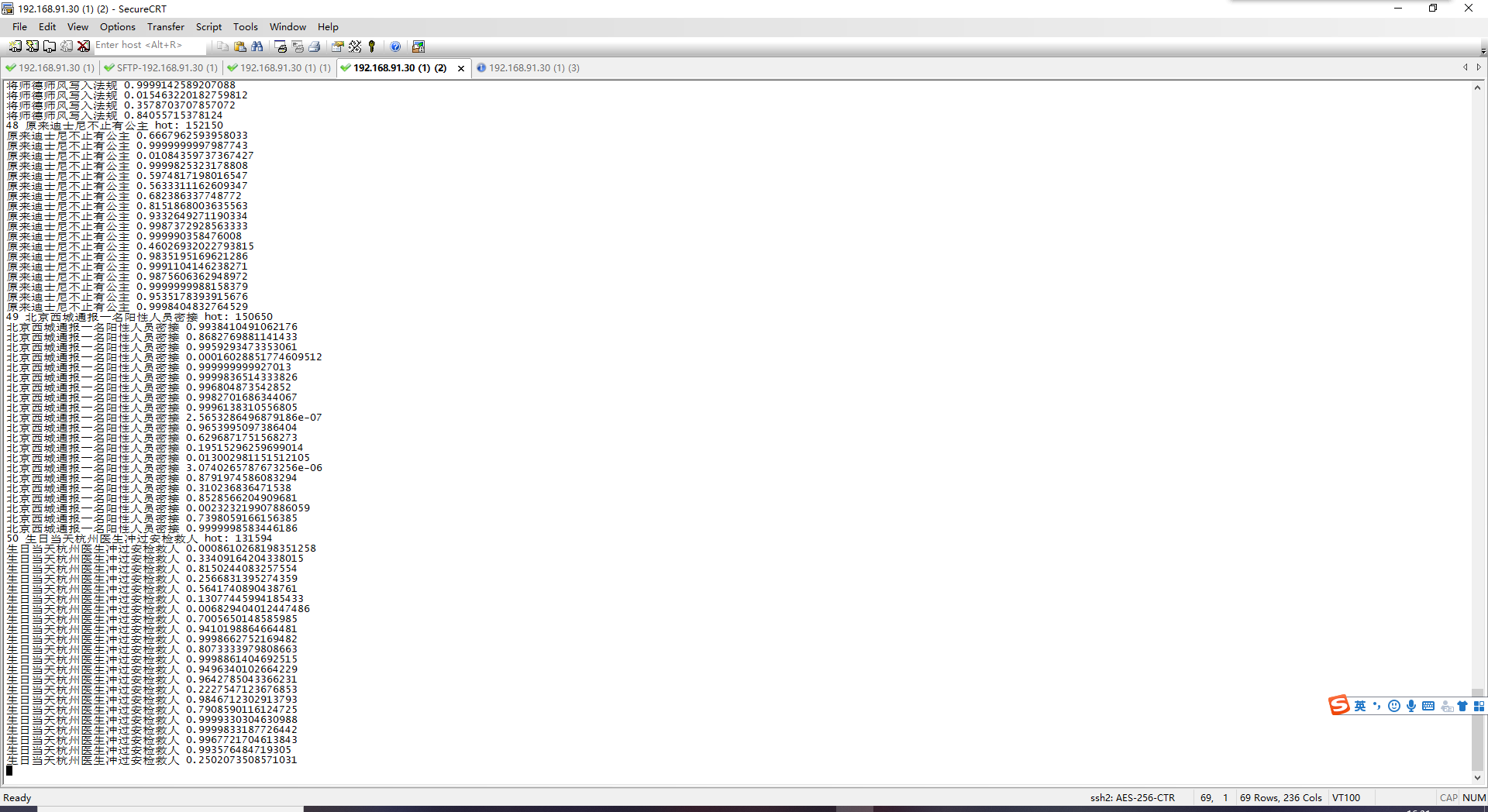
三、工程文件解释 1.producer 将爬虫整合到producer生产者中。获取经过观察,微博内容存在于td-02标签之中,按照整体页面结构循环读取出标签中的内容。得到爬取的内容并通过zookeeper向kafka cluster集群中指定的topic发送。
爬虫函数需要观察网页结构布局、注意不同网页数据所在的位置
微博查看需要注意登录状态,用户headers需要正确添加
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 import jsonfrom kafka import KafkaProducerfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import *from pyspark.sql.types import *import requestsfrom lxml import etreefrom bs4 import BeautifulSoupimport timeimport reimport urllib.parsefrom weibo_top_sentiment import *bayesSentimentModel = BayesSentiment() headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36' , 'Cookie' : 'SINAGLOBAL=8952596771843.973.1619269017487; SCF=AqdkznlYHewYaGz11U_Ewp7RO2xO2Xd4cvwl_zD0tRWF0Wm2BeSnOv3Y-wXnvZYRLf0ffP44xgWozS0YFaAM8eI.; ALF=1663466356; UOR=cn.bing.com,weibo.com,localhost:8888; SUB=_2A25MZGr7DeRhGeNI7VUV8y_IzTiIHXVvp3azrDV8PUJbkNAKLVjCkW1NSCumaJHCc-hZj7e5J3Q4wPOjB0zVojev; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFsS52AoM-aTTy1EieyUG8Z5NHD95QfSoqNShepShqXWs4Dqcj6i--RiKLFiKyFi--NiKnEiK.Ei--4i-2fi-82i--Xi-zRiKy2i--fiKysi-8si--fiKyWi-27i--RiKLFiKyF; _s_tentry=-; Apache=8470921214117.056.1634791170888; ULV=1634791170895:23:7:1:8470921214117.056.1634791170888:1634256856266' } def get_top (producer ): url = "https://s.weibo.com/top/summary" r = requests.get(url, headers=headers) soup = BeautifulSoup(r.text, "html.parser" ) for i in soup.select('tbody tr' ): numtmp = i.select('.ranktop' ) if len (numtmp): try : num = int (numtmp[0 ].string) title = i.select('.td-02 a' )[0 ].string hot_score = i.select('.td-02 span' )[0 ].string.split(' ' )[-1 ] print (num, title, 'hot:' , hot_score) result = get_weibo_list("https://s.weibo.com//weibo?q=%23" + title[0 ] + "%23&Refer=top" ) except ValueError as e: continue for each in result: sentiment_score = bayesSentimentModel.predict(each) print (title, sentiment_score) msg = {"title" : title, "time" : time.strftime("%Y-%m-%d %H:%M:%S" , time.localtime()),"sentiment_score" : sentiment_score} producer.send('weibotop' , key='ff' , value=json.dumps(msg)) time.sleep(2 ) def get_weibo_list (url ): r = requests.get(url, headers=headers) bs = BeautifulSoup(r.text) body = bs.body div_m_main = body.find('div' , attrs={'class' : 'm-main' }) div_m_flex1 = div_m_main.find('div' , attrs={'class' : 'woo-box-flex' }) div_m_wrap = div_m_flex1.find('div' , attrs={'class' : 'woo-box-flex' , 'id' : 'pl_feed_main' }) div_m_con_l = div_m_wrap.find('div' , attrs={'class' : 'main-full' }) data_div = div_m_con_l.findAll('div' , attrs={'class' : 'card-wrap' , 'action-type' : 'feed_list_item' }) weibo_list = [] for each_div in data_div: div_card = each_div.find('div' , attrs={'class' : 'card' }) div_card_feed = div_card.find('div' , attrs={'class' : 'card-feed' }) div_content = div_card_feed.find('div' , attrs={'class' : 'content' }) p_feed_list_content = div_content.find('p' , attrs={'class' : 'txt' , 'node-type' : 'feed_list_content' }) content_text = p_feed_list_content.get_text() p_feed_list_content_full = div_content.find('p' , attrs={'class' : 'txt' , 'node-type' : 'feed_list_content_full' }) if p_feed_list_content_full: content_text = p_feed_list_content_full.get_text() weibo_list.append(content_text.strip()) return weibo_list producer = KafkaProducer(bootstrap_servers='localhost:9092' , key_serializer=lambda k: json.dumps(k).encode(), value_serializer=lambda v: json.dumps(v).encode()) while True : get_top(producer=producer) time.sleep(600 )
2.数据处理与模型训练 process函数借助re包与jieba分词对于采集到的内容进行去重、去噪等预处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #去除url text = re.sub("(https?|ftp|file)://[-A-Za-z0-9+&@#/%=~_|]"," ",text) #去除@xxx(用户名) text = re.sub("@.+?( |$)", " ", text) #去除{%xxx%}(地理定位,微博话题等) text = re.sub("\{%.+?%\}", " ",text) #去除#xx#(标题引用) text = re.sub("\{#.+?#\}", " ", text) #去除【xx】(里面的内容通常都不是用户自己写的) text = re.sub("【.+?】", " ", text) #数据集中的噪声 text = re.sub('\u200b'," ",text) #分词 words = [w for w in jieba.lcut(text) if w.isalpha()]
加载训练集与测试集建模并将训练好的模型保存
贝叶斯方法是机器学习中一个有着悠久历史、坚实理论基础的方法。朴素贝叶斯的思想基础是:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。本项目采用多项式贝叶斯算法MultinomialNB。是朴素贝叶斯的变体,常用与文本分类。详细理论需要多花时间研究,最最通俗来讲,在本项目中的体现在于将得出的结果与0和1两个极端值相比较,越趋近于0就认为负面情绪占比更多,越趋近于1就认为正面情绪占比更多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import re import jiebaimport sysimport pandas as pdfrom sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn import metricsimport pickledef load_corpus (path ): data = [] with open (path,'r' ,encoding='utf-8' )as f: for line in f : [_,sentiment,content] = line.split("," ,2 ) content = process(content) data.append((content,int (sentiment))) return data def process (text ): text = re.sub("(http?|ftp|file)://[-A-Za-z0-9+%@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#?%=~|]" ," " ,text) text = re.sub("@.+?( |$)" ," " ,text) text = re.sub("\{%.+?%\}" ," " ,text) text = re.sub("\{#.+?%\}" ," " ,text) text = re.sub("【.+?】" ," " ,text) text = re.sub("\u200b" ," " ,text) text = re.sub("n" ," " ,text) words = [w for w in jieba.lcut(text) if w.isalpha()] result =" " .join(words) return result TRAIN_PATH = "/opt/train.txt" TEST_PATH = "/opt/test.txt" def train (): stopwords = [] with open ('/opt/stopwords.txt' ,'r' ,encoding='utf-8' )as f: for w in f : stopwords.append(w.strip()) train_data = load_corpus(TRAIN_PATH) test_data = load_corpus(TEST_PATH) df_train = pd.DataFrame(train_data,columns=["words" ,"label" ]) df_test = pd.DataFrame(test_data,columns=["words" ,"label" ]) vectorizer = CountVectorizer(token_pattern='\[?\w+\]?' ,stop_words=stopwords) x_train = vectorizer.fit_transform(df_train['words' ]) y_train = df_train["label" ] x_test = vectorizer.transform(df_test["words" ]) y_test = df_test["label" ] clf = MultinomialNB() clf.fit(x_train,y_train) y_pred =clf.predict(x_test) print (metrics.classification_report(y_test,y_pred)) print ("准确率:" ,metrics.accuracy_score(y_test,y_pred)) with open ('bayes_model.pkl' ,'wb' )as f: pickle.dump([clf,vectorizer],f) class BayesSentiment (object ): def __init__ (self ): with open ('bayes_model.pkl' ,'rb' ) as f: self.clf,self.vectorizer = pickle.load(f) def predict (self,sentence ): sentenceprocessed = [process(sentence)] vec = self.vectorizer.transform(sentenceprocessed) return self.clf.predict_proba(vec)[0 ][1 ] if __name__ == '__main__' : train()
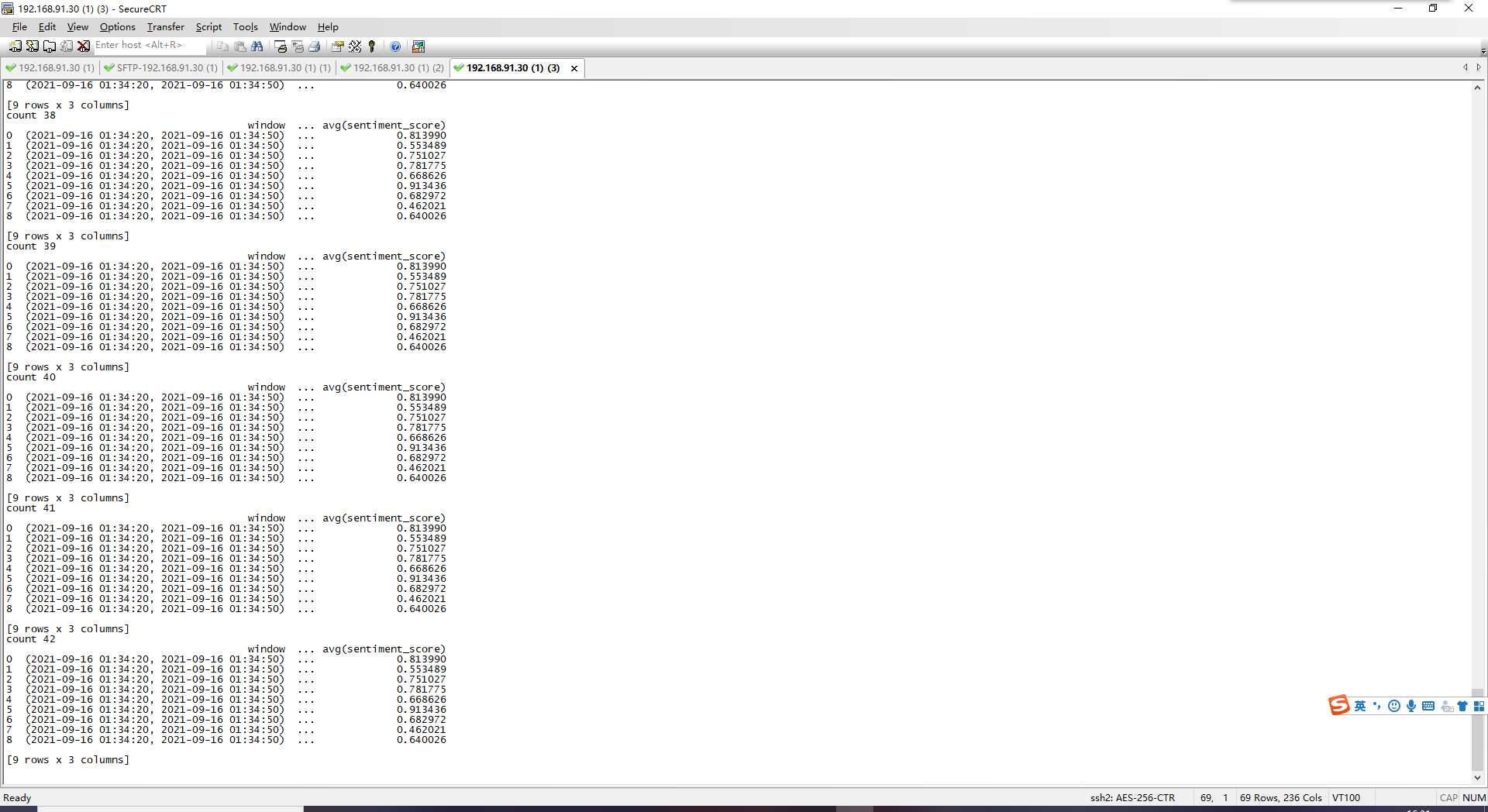
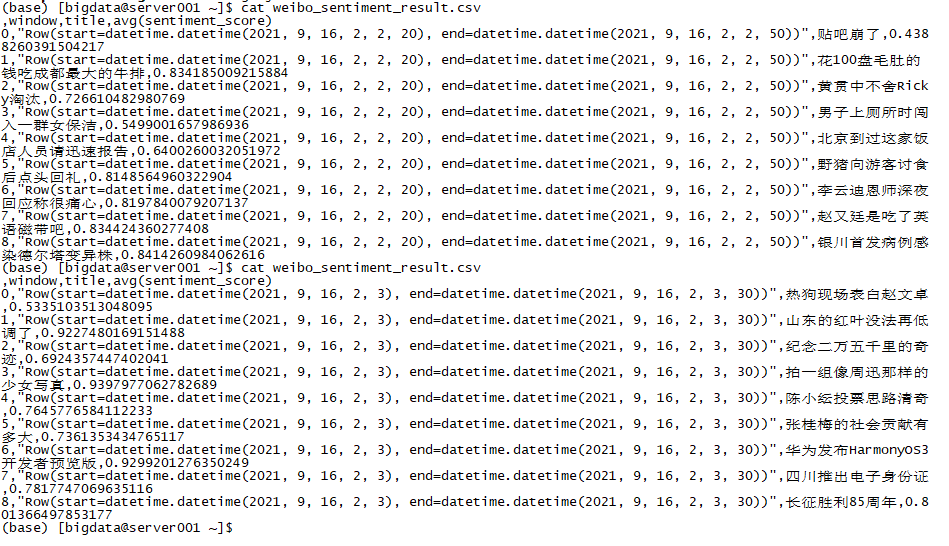
3.consumer consumer消费者从kafka集群中broker指定的topic中读取消息,并将内容持久化为csv文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import sysimport jsonfrom pyspark.sql import SparkSessionfrom pyspark.sql.functions import *from pyspark.sql.types import *from IPython.display import clear_outputimport seaborn as snsimport matplotlibimport matplotlib.pyplot as pltimport time@udf(returnType=StringType( ) def gettitle (column ): jsonobject = json.loads(column) jsonobject = json.loads(jsonobject) if "title" in jsonobject: return str (jsonobject['title' ]) return "" @udf(returnType=DoubleType( ) def getscore (column ): jsonobject = json.loads(column) jsonobject = json.loads(jsonobject) if "sentiment_score" in jsonobject: return float (jsonobject['sentiment_score' ]) return 0.5 if __name__ == "__main__" : if len (sys.argv) != 4 : print ("参数错误" , file=sys.stderr) sys.exit(-1 ) spark = SparkSession\ .builder\ .appName("WeiboSpark" )\ .getOrCreate() sc = spark.sparkContext sc.setLogLevel("ERROR" ) bootstrapServers = sys.argv[1 ] subscribeType = sys.argv[2 ] topics = sys.argv[3 ] lines = spark\ .readStream\ .format ("kafka" )\ .option("kafka.bootstrap.servers" , bootstrapServers)\ .option(subscribeType, topics)\ .load() kafka_value_tb = lines.selectExpr("CAST(value AS STRING) as json" , "timestamp" ) weibo_table = kafka_value_tb.select(gettitle(col("json" )).alias("title" ), getscore(col("json" )).alias("sentiment_score" ), col("timestamp" )) stat_avg = weibo_table.groupBy(window(col("timestamp" ), "30 seconds" , "10 seconds" ), col("title" )).avg("sentiment_score" ).where("unix_timestamp(window.end)=int(unix_timestamp(current_timestamp)/10)*10" ) queryStream = (stat_avg.writeStream.format ("memory" ).queryName("weibotop" ).outputMode("complete" ).start()) try : i = 1 while True : print ("count" , str (i)) df = spark.sql( """ select * from weibotop""" ).toPandas() print (df) df.to_csv("weibo_sentiment_result.csv" ) time.sleep(10 ) i = i + 1 except KeyboardInterrupt: print ("process interrupted" ) queryStream.awaitTermination()
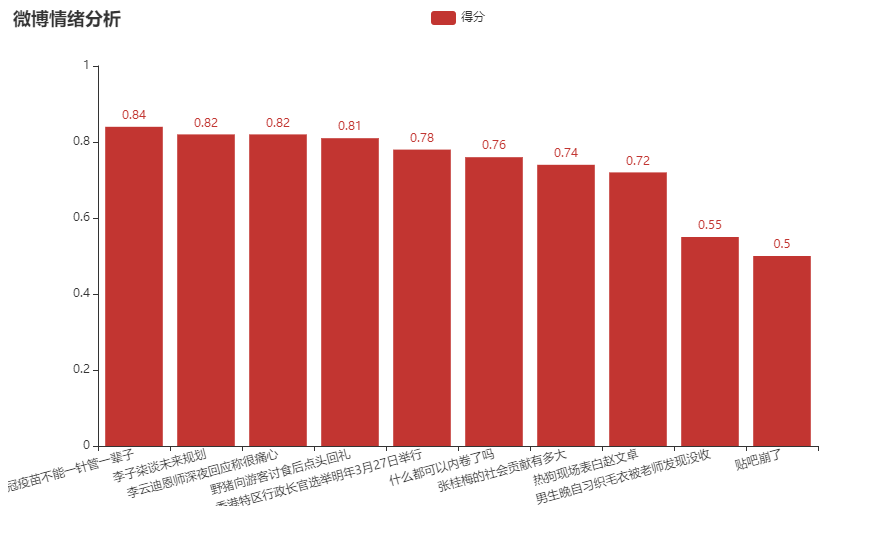
4.可视化 pyecharts柱状图与flask框架可视化。都是第三方库,使用比较简单方便。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from flask import *from jinja2 import Markupfrom pyecharts import options as optsfrom pyecharts.charts import Barimport randomimport pandas as pdapp = Flask(__name__) @app.route("/" def index (): bar = gen_data_bar() return Markup(bar.render_embed()) def gen_data_bar (): df = pd.read_csv('weibo_sentiment_result.csv' ) title_names = [] avg_scores = [] df = df.sort_values(by="avg(sentiment_score)" ,ascending=False ) for index in range (df.shape[0 ]): title_names.append(df['title' ].iloc[index]) avg_scores.append(str (round (float (df['avg(sentiment_score)' ].iloc[index]),2 ))) bar = (Bar() .add_xaxis(title_names) .add_yaxis('得分' ,avg_scores) .set_global_opts(title_opts=opts.TitleOpts(title="微博情绪分析" ,subtitle="" ),xaxis_opts=opts.AxisOpts(name="" ,axislabel_opts={"rotate" :15 },name_rotate=60 )) ) return bar if __name__=='__main__' : app.run(host='192.168.91.30' ,port='8001' ,processes=1 )
四、项目流程 1.虚拟机环境配置好,准备好训练好的模型,开启kafka 1 2 3 4 5 6 7 8 9 10 11 12 1、关闭防火墙(第一个shell窗口) sudo systemctl stop firewalld 2、启动kafka zookeeper服务器 /opt/software/kafka_2.12-2.7.0/bin/zookeeper-server-start.sh /opt/software/kafka_2.12-2.7.0/config/zookeeper.properties 3、启动kafka broker服务器(第二个shell窗口) /opt/software/kafka_2.12-2.7.0/bin/kafka-server-start.sh /opt/software/kafka_2.12-2.7.0/config/server.properties 4、服务器启动后,创建topic(第三个shell窗口) /opt/software/kafka_2.12-2.7.0/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic weibotop
2.Producer生产者获取微博热搜内容,进行评分并发送 1 python weibo_top_producer.py
3.Consumer消费者接收内容,并持久化保存 1 spark-submit --packages org.apache.spark:spark-streaming-kafka-0-10_2.12:3.0.1,org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.1 weibo_top_consumer.py localhost:9092 subscribe weibotop
4.可视化呈现 1 2 python weibo_top_visual_pyecharts.py 按flask配置在浏览器输入http://192.168.91.30:8001/