Write a Python program to calculate the ROI (Return of investment) with the steps below
Create a variable earning and assign it value to 3765432.
Create the variable invest and assign it value to 1000000.
Create the variable roi and assign the formula $roi = \frac{Earnings - Invest}{Invest}$ You can find more Markdown syntax about writing mathematical expressions here
Write a Python program to get the user input as a string and output the result in uppercase, lowercase and title. You may find the input() function here. You may also find the String methods here
1 2 3 4 5 6 7 8
x = input("type here plz:") print(x.upper()) print(x.lower()) print(x.title()) #type here plz:ABCDKSF #ABCDKSF #abcdksf #Abcdksf
Lab2
Write a Python program to find the maximum value of three numbers. You are REQUIRED to implement a function named max() to take three arguments and print print the result. e.g. max(5,56, 12) 56
1 2 3 4 5 6 7 8 9 10
defmax(num1,num2,num3): list = [num1,num2,num3] tmp = 0 for i inlist: if i > tmp: tmp = i print(tmp) max(5,56,12) #56
Write a Python program to reverse a string. You are REQUIRED to implement a function named reverse() to take a string and return the result. Hint
1 2 3 4 5 6 7 8 9 10
defrevers(str1): rstr = '' for i inrange(1,len(str) + 1): rstr = rstr + str1[-i] print(rstr)
text = input("typing a string plz:") revers(text) #typing a string,plz:jack #kcaj
Write a Python program to create and print a list where the values are first N square of numbers. You are REQUIRED to implement a function named printSquare() to take n where n is an positive integer.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
# Please write your code here # if 'first N' means input:6 -> output:[0, 1, 4, 9, 16, 25] defprintSquare(n): list = [] for i inrange(0,int(n)): list.append(i**2) returnlist
# if 'first N' means input:5 -> output:[0, 1, 4, 9, 16, 25] defprintSquare(n): list = [] for i inrange(0,int(n) + 1): list.append(i**2) returnlist
num = input("Please input an integer") print(printSquare(num))
Below is an exmaple to accept an phone number and format the result. You can use it to format for the currency as well.
1 2 3 4 5 6 7
phonenumber = input("plaz enter a phone number") list2 = list(phonenumber) list2.insert(4,'-') phonenumber = "".join(list2) print(phonenumber) #plaz enter a phone number12345678 #1234-5678
If we wish to deal with the wordings in a sentence
1 2 3 4 5 6 7 8
sentence = input("plz input a sentence") words = sentence.split() print("First word:",word[0]) print("last word",words[-1]) #plz input a sentencetoday is a good day #['today', 'is', 'a', 'good', 'day'] #First word today #last word day
Sets
1 2 3 4 5 6 7 8 9 10
poem = "Mary had a little lamb, little lamb, little lamb, Mary had a little lamb, Its fleece was white as snow" poem = poem.replace(',','') print(words) words = set(words) print(words) print("There are", len(words), "unique words in this peom")
#['Mary', 'had', 'a', 'little', 'lamb', 'little', 'lamb', 'little', 'lamb', 'Mary', 'had', 'a', 'little', 'lamb', 'Its', 'fleece', 'was', 'white', 'as', 'snow'] #{'a', 'Mary', 'was', 'Its', 'white', 'as', 'snow', 'lamb', 'fleece', 'little', 'had'} #There are 11 unique words in this peom
message ='Python is an interpreted high-level general-purpose programming language. Its design philosophy emphasizes code readability with its use of significant indentation. Its language constructs as well as its object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects.[30] Python is dynamically-typed and garbage-collected.' for char in message: if char >= 'a'and char <= 'z': smallLetters[char] += 1 print(smallLetters)
Write a Python program to search a list for the first int object which is divisible by 13. You may test your program with the list [12, “COMP”, 999.9, “2022”, 26, “Great”] Hint isinstance()
1 2 3 4 5 6 7 8 9 10 11 12
## Please write your code here list = [12, "COMP", 999.9, "2022", 26, "Great"] for item inlist: ifisinstance(item, int): #This is an integer #print(item, "Check for integer type pass!") if item % 13 == 0: #This is divisble by 13 #print(item, "Check for divisible by 13 pass!") print(item, "is divisible by 13") break
26 is divisible by 13
Write a Python program to convert the 24 hour clock to a 12 hour clock format. For example, to get an user input 1532, then output
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
## Please write your code here timeIn = input("Please input a time in 24 hour format e.g. 1532 or 0945") hour = int(timeIn[:2]) minute = int(timeIn[2:]) if minute < 10: minute = '0' + str(minute) else: minute = str(minute) if (hour > 12): time = str(hour - 12) + ':' + minute + 'pm' elif hour == 12: time = '12' + ':' + minute + 'pm' elif hour == 0: time = '12' + ':' + minute + 'am' else: time = str(hour) + ':' + minute +'am'
print(time)
Please input a time in 24 hour format e.g. 1532 or 0945 1532
3:32pm
HW1
Write a Python program with function to sum of two given integers. However, if the sum is between 15 to 20 it will return 20.
For example:
if a=10, b =6, it will return 20
if a=10, b=2, it will return 12
if a=10, b=12, it will return 22
DONOT PRINT IN THE FUNCTION.
1 2 3 4 5 6 7 8 9 10 11 12
defsum(x, y): #Write your code below result = x + y if result >= 15and result <= 20: return20 else: return result
Write a Python program to check if a number is positive, negative or zero. Hint: if elif else
num is provided in the first line using input(“Input a number”). You can input any numbers you like.
1 2 3 4 5 6 7 8 9
num = float(input("Input a number: ")) ##Write your code with if elif else below if num > 0: print('positive') elif num == 0: print('zero') else: print('negative')
Input a number: -1
negative
Write a Python program to calculate the sum of three given numbers, if the values of each number are equal then return thrice of their sum else please return their sum directly.
For example,
if x = 3, y = 3, z = 3, return 27
if x = 1, y = 2, z = 3, return 6
1 2 3 4 5 6 7 8 9 10
defsum_thrice(x, y, z): if x == y and y == z: return x*x*x else: return x + y +z
Write a Python program to find whether a given number is even or odd, print out an appropriate message to users.
For example:
if the number is even, print “The number is even” otherwise print “The number is odd”
1 2 3 4 5 6 7 8 9
defjudgenum(num): if num%2 == 0: print('The number is even') else: print('The number is odd')
judgenum(1) judgenum(2) judgenum(3)
The number is odd
The number is even
The number is odd
Write a Python program to get the volume of a sphere with given radius values. The volume of the sphere is : $V = 4/3 × π × r^3$. DONOT PRINT IN FUNCTION
1 2 3 4 5 6 7 8 9 10
import math
defvolume(radius): ##show your codes v = (4/3) * math.pi * pow(radius,3) return v
print(volume(4)) print(volume(5)) ##PLEASE ENSURE THAT YOUR RESULTS ARE DISPLAYED BY PRINT HERE.
268.082573106329
523.5987755982989
Write a Python program to append list1 to list2.
1 2 3 4 5 6
list1 = [1, 2, 3, 0] list2 = ['Red', 'Green', 'Black'] ##Write your code blew and rember to display them list3 = list1 + list2 list2 = list3 print(list2)
[1, 2, 3, 0, 'Red', 'Green', 'Black']
Write a Python program to get the largest number from a list.
For example: We can use max([1,2,3]) to get the largest number of a list. Now, please do not use max() and write a fuction for this purpose yourself.
Requirements:
a. Donot use max(a list) to get the largest number, otherwise you can only get the minimum point.
b. Donot print the value inside the function. Just return them.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
defmax_num_in_list(list): # tmp = 0 # for i in list: # if i > tmp: # tmp = i # return tmp
tmp = 0 for i inrange(0,len(list)): iflist[i] > tmp: tmp = list[i] return tmp
Write a Python program to get a string from a given string where all occurrences of its first char have been changed to ‘$’, except the first char itself.
1 2 3 4 5 6 7 8 9 10 11 12
defchange_char(str1): s = list(str1) for i inrange(1,len(s)): if s[i] == s[0]: s[i] = '$' res = ''.join(s) return res
print(change_char('restart'))
resta$t
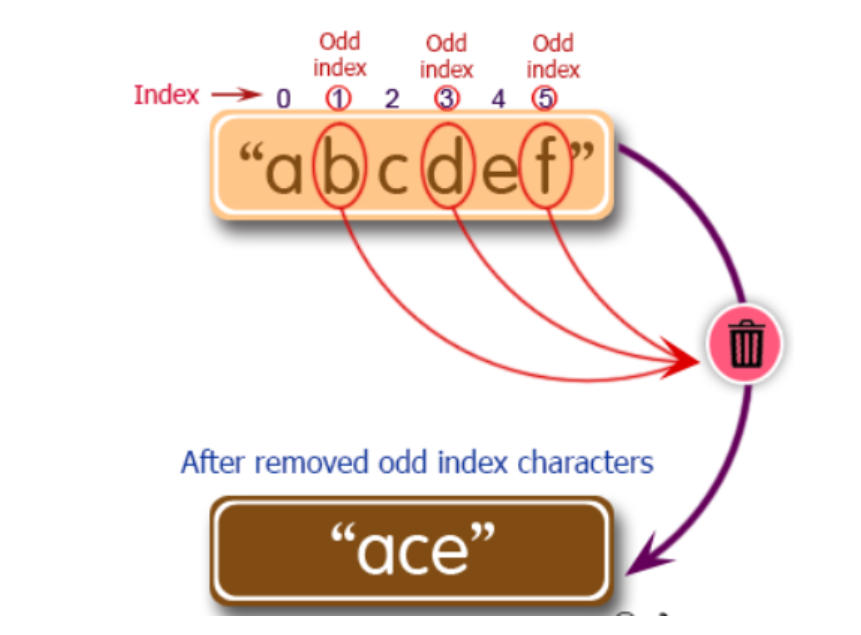
11.Write a Python program to remove the characters which have odd index values of a given string.
1 2 3 4 5 6 7 8 9 10 11 12
defodd_values_string(str): s = list(str) s2 = [] for i inrange(0,len(s)): if i % 2 == 0: s2.append(s[i]) res = ''.join(s2) return res
import os path = './data' emails = [] for file in os.listdir(path): file = open(path + '//' + file, 'r') for line in file: if'@'in line: emails.append(line.rstrip('\n')) file.close() emails.sort() print(emails)
withopen('week4.txt','w') as file: file.write("This is the first line\n") file.write("This is the second line\n") file.write("The end\n") #new content to an existinf file withopen('week4.txt','a') as file: file.write("Extra line added\n")
Q4 Get current directory
1 2
import os os.getcwd()
1
'C:\\Users\\f2401539\\Desktop'
Q5
1 2 3 4 5 6
file = open(os.getcwd() + '\districts.txt','r') districts = [line for line in file] districts.sort() for i inrange(0,18): print(districts[i]) file.close()
courses = [['Course Code', 'Year', 'Semester','Course Name'], ['COMP7035', '2022-23', 'Sem A', 'Python for Data Analytics and Artificial Intelligence'], ['COMP1007', '2021-22', 'Sem B','Introduction to Python and Its Applications']] f = open('courses.csv','w') with f: writer = csv.writer(f) for row in courses: writer.writerow(row)
1 2 3 4 5 6 7 8
import csv f = open('courses.csv','r')
with f: reader = csv.reader(f) for row in reader(f) for row in reader: print(row)
1 2 3 4 5 6
['Course Code', 'Year', 'Semester', 'Course Name'] [] ['COMP7035', '2022-23', 'Sem A', 'Python for Data Analytics and Artificial Intelligence'] [] ['COMP1007', '2021-22', 'Sem B', 'Introduction to Python and Its Applications'] []
Lab5 Numpy
create an array of the integers from 20 to 50
1 2 3
import numpy as np array = np.arange(20,51) print(array)
df = read_csv('elderly.csv') year = df['Year'].values.tolist() print(year) sixtyFiveAbove = df['65 years old and above'].values.tolist() print(sixtyFiveAbove)
8. Write down as many ways of forming a list that contains the values of Series elements
1 2 3 4 5 6 7 8
val_1 = pd_series_dict.to_list() val_2 = []
for idx, ival in pd_series_dict.iteritems(): val_2.append(ival) val_3 = pd_series_dict.values val_tmp = pd_series_dict.index val_4 = [pd_series_dict[ikey] for ikey in pd_series_dict.index]
9. Calculate the proportion of elements that are larger than the mean value of the Series
Subset of the above Data Series: 11 11 12 12 13 13 14 14 15 15 dtype: int64
Lab9 Pandas_2
1 2
import numpy as np import pandas as pd
1. Write codes to create two DataFrames df_left, df_right, with the columns as “[key, lval1, lval2]” and “[key, rval1, rval2]”, and the values are “[a,b,c]”, and “[b,c,d]” respectively. Generate random numbers with normal distribution to for the “lval” and “rval” elements
key lval1 lval2 0 a -0.306740 0.370246 1 b -1.633727 -0.351369 2 c 1.558975 -0.179692 --------- key rval1 rval2 0 b -0.036699 0.724182 1 c -1.241680 -1.695795 2 d 1.580775 -1.271330
2. Compute the left outer join of df_left and df_right, check out the results
1 2
left_merge = pd.merge(left_df, right_df, how = 'left') print(left_merge)
1 2 3 4
key lval1 lval2 rval1 rval2 0 a -0.306740 0.370246 NaN NaN 1 b -1.633727 -0.351369 -0.036699 0.724182 2 c 1.558975 -0.179692 -1.241680 -1.695795
3. Change the name “key” of df_left to “key_left”, re-run step 2 and see what happens
1
left_df.columns = ['key_left','lval1','lval2']
4. Compute the right outer join of df_left and df_right in step 2, check out the results
1 2
right_merge = pd.merge(left_df, right_df, how = 'right') print(right_merge)
1 2 3 4
key lval1 lval2 rval1 rval2 0 b -1.633727 -0.351369 -0.036699 0.724182 1 c 1.558975 -0.179692 -1.241680 -1.695795 2 d NaN NaN 1.580775 -1.271330
5. Compute the full outer join of df_left and df_right in step 2, check out the results
1 2
outer_merge = pd.merge(left_df, right_df, how = 'outer') print(outer_merge)
1 2 3 4 5
key lval1 lval2 rval1 rval2 0 a -0.306740 0.370246 NaN NaN 1 b -1.633727 -0.351369 -0.036699 0.724182 2 c 1.558975 -0.179692 -1.241680 -1.695795 3 d NaN NaN 1.580775 -1.271330
6. Compute the inner join of df_left and df_right in step 2, check out the results
1 2
inner_merge = pd.merge(left_df, right_df, how = 'inner') print(inner_merge)
1 2 3
key lval1 lval2 rval1 rval2 0 b -1.633727 -0.351369 -0.036699 0.724182 1 c 1.558975 -0.179692 -1.241680 -1.695795
7. Get the floating value columns of df_left (lval1,lval2), get the square root of the absolute values using apply
10. Get the data of “Countries and dependencies by area” from wiki and save to the excel excluding index
1 2 3 4 5 6 7 8 9
import requests url_wiki = 'https://en.wikipedia.org/wiki/List_of_countries_and_dependencies_by_area' r = requests.get(url_wiki,headers ={'User-Agent':'Mozilla/5.0 (Windows NT 10.0;Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124Safari/537.36'})
data = pd.read_html(r.text) print([idata.shape for idata in data]) data_area = data[1] print(data_area) data_area.to_excel('area_info.xlsx',index = False)
Lab10 Sweetviz
1. Load the BankChurners_clean.csv (download it from Moodle) into the pandas DataFrame
1 2 3 4 5 6 7 8
import pandas as pd import numpy as np import sweetviz as sv
4. For the Customer_Age, let us display the histogram within 5 groups (30,40, 50, 60, 70). What is the proportion of people over 70 years old in the test set? For the test set, Which age group has the lowest rate for “true attrition flag”?
1.Rather than identifying the actual number, we want to classify whether the digit image contains an odd number. Modify the data generator to produce correct data samples from the MNIST dataset
import keras, linecache, random classDataGenerator(keras.utils.Sequence): 'Generates data for Keras' def__init__(self, csv_path, indexes): #initilizes some variables self.csv_path = csv_path self.norm_factor = 255.0 self.indexes = indexes #random.shuffle(self.indexes) def__len__(self): #return the total number of samples in dataset returnlen(self.indexes) def__getitem__(self, index): #create one sample according to the index line_index = self.indexes[index] line_str = lineache.getline(self.csv_path, line_index) line_val = [int(i) for i in line_str.split(',')] label = line = line[0]%2 feat = np.array(line_val[1:])/self.norm_factor return feat, label indexes = [i for i inrange(60000)] train_index = indexes[6000:] val_index = indexes[:6000] train_set = DataGenerator('mnist_train.csv', train_index) val_set = DataGenerator('mnist_train.csv', val_index) print(len(train_set)) print(len(val_set)) cnt = 0 for x, y in train_set: print(y) cnt = cnt + 1 if cnt >= 5: break
2.We want to make the input feature normalized to [-1,1]. What shall we do?
from sklearn import datasets from sklearn.moddel_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.decomposition import PCA